


Big data: le dessous des cartes
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
Pour se distinguer aujourd’hui, il est de bon ton pour les entreprises de mettre en avant la quantité de données qu’elles peuvent collecter et de brandir cette capacité comme l’avantage concurrentiel suprême ! Data is the new oil, effet réseau des données, autant de poncifs marketing de plus en plus utilisés pour apparaître moderne et obtenir la faveur des investisseurs. Un sommet du genre se trouve dans le document d’introduction en bourse de l’AssurTech Lemonade:
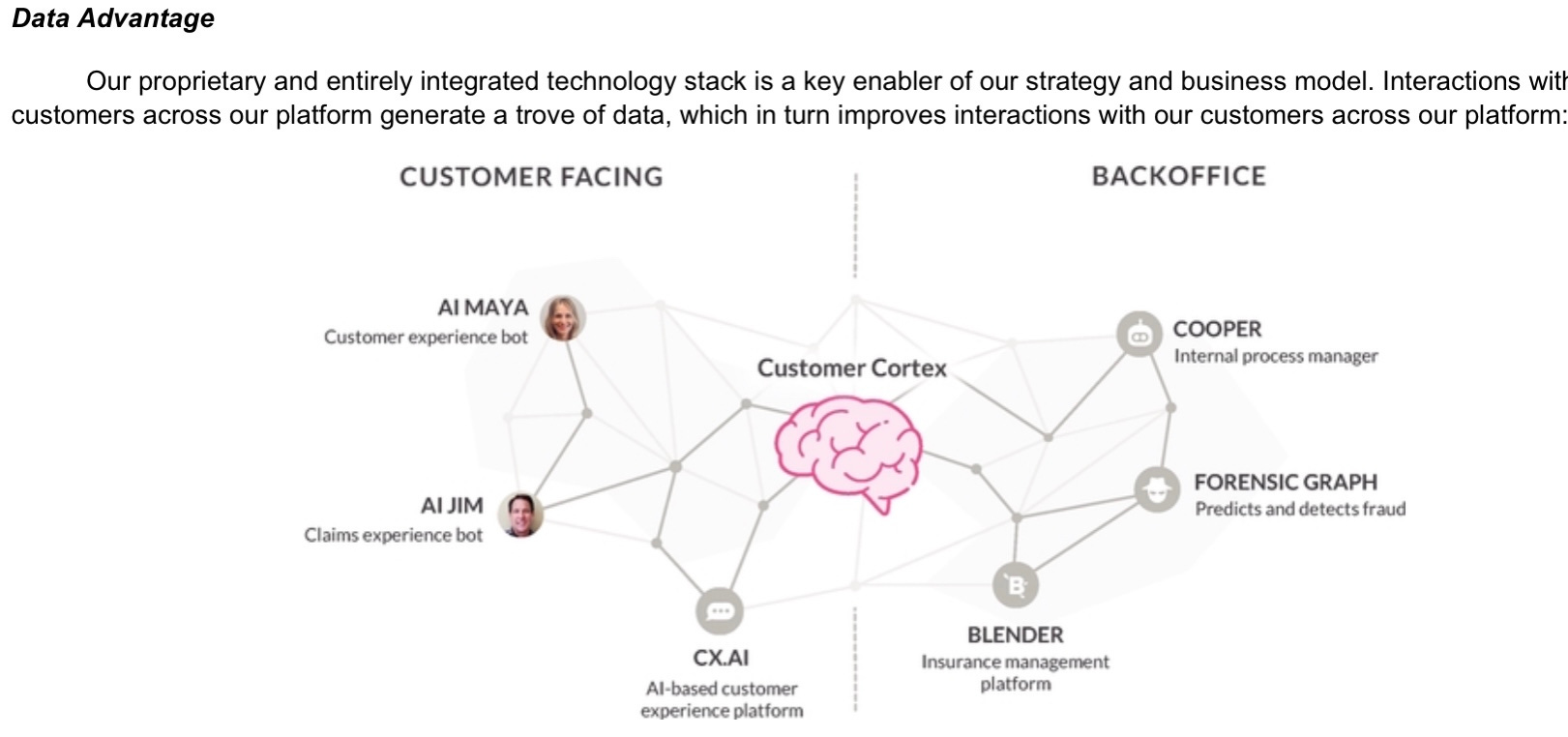
Le document énumère toutes les façons dont l’intelligence artificielle nourrie par l’abondance de données propriétaires améliore l’expérience des clients tout en réduisant les coûts. Le cerveau du consommateur est cerné et ravi par l’IA. Cela m’inspire deux questions:
Les bonnes données sont elles prises en compte ? Une bonne interaction humaine ne vaut elle pas 100 bots, surtout quand on a un sinistre à régler ou une décision d’assurance à prendre ? Vendre de l’assurance, c’est vendre de la confiance. Fait on confiance à un bot ?
Les données sont elles utilisées pour le bon objectif ? La clé du succès pour une compagnie d’assurance est la segmentation. Les données peuvent être un atout formidable pour segmenter, trouver des gens qui se ressemblent (cf la publicité chez Facebook). Il n’est pas clair que Lemonade ait cette priorité en tête.
J’en tire la conclusion suivante: avoir les données c’est bien, avoir les données pertinentes, c’est mieux. L’intelligence artificielle, un automatisme-pas plus- doit être dirigée vers les bons objectifs, en s’appuyant sur des données utilisables légalement et protégées. Cela demande une forte évolution dans le monde des entreprises, pour que l’utilisation des données passe du slogan à la machine de guerre. Les données ne valent rien en tant que tel. A l’époque du RGPD, elles sont même plutôt un passif. C’est l’orchestration des données qui en fait toute la valeur.
On vante l’effet réseau des données. La réalité n’est-elle pas une abondance causant une dépréciation très forte de la valeur unitaire de ces données ? Comment alors renverser la vapeur et organiser la machine de guerre ?

Bref historique du traitement des données
Il fut un temps où la puissance de calcul des microprocesseurs (CPU), la capacité de stockage et donc la masse de données traitées évoluaient à l’unisson, suivant la loi de Moore. Les entreprises construisaient leur parc informatique (stockage, CPU et réseau) pour exploiter de manière intelligente leurs données. Celles-ci étaient stockées d’abord dans des base de données hiérarchiques (IBM) qui sont devenues relationnelles (Oracle) pour gagner en souplesse d’utilisation. Les différentes divisions de l’entreprise avaient chacune leurs bases de données, lesquelles étaient consolidées dans une base de données centrale où les données étaient structurées (comme disposées sur un tableau Excel géant) pour la prise de décision, protégées des destructions et du piratage. Le réceptacle de ces données officielles s’appelait l’entrepôt de données, un mix hardware/software sur site installé généralement par IBM ou Oracle, vendu très cher. Les données étaient précieuses car cher à stocker et à protéger, on cherchait à en tirer le maximum, en éviter le gaspillage. Cette organisation de l’intelligence économique a permis des avancées décisives dans le marketing, la logistique et la percée des multinationales dans les années 90. IBM a fait avancer Oracle ( la première base de données relationnelle était IBM !) qui a fait avancer SAP, qui a fait avancer Starbucks.
Un petit grain de sable s’est infiltré dans cette belle mécanique au début des années 2000: La taille des transistors (unité de base des CPU) ne suivait plus la loi de Moore. Parallèlement la capacité de stockage continuait sa croissance vertigineuse. L’internet apportait de nombreuses nouvelles données à traiter, données dont le coût de stockage s’effondrait. Cela forcément créait un embouteillage au niveau du traitement des données. Les conséquences ont été profondes pour l’industrie informatique:
Il a fallu regrouper les CPU dans des centres de données plus importants, cela a donné le cloud: Salesforce en 2000, Amazon Web Services en 2006, etc. Il devenait trop coûteux de regrouper tant de puissance de calcul dans son entreprise, la mutualisation s’est imposée.
La qualité des réseaux de communication n’étant pas à la hauteur jusque dans les années 2010, les données ne pouvaient circuler facilement entre serveurs lointains. Il fallait traiter les données près de leur source. C’était à l’avantage des IBM et Oracle qui vendait leur solution d’entrepôt sur site très cher ! le cloud censé débloquer la puissance de traitement des données créait une nouvelle impasse: la circulation de celles-ci. Et pendant ce temps les données s’accumulaient, à la valeur douteuse. Il devenait impraticable et trop coûteux de les stocker dans les entrepôts.
Pour stocker ce déluge de données arrivant de toutes parts (web, applications mobiles, censeurs divers), on a inventé le concept de lac de données, capable d’emmagasiner des masses de données structurées ou non. Le stockage était distribué, décentralisé sur des ordinateurs bon marché.Le tableau Excel géant (l’entrepôt) était remplacé par des fichiers épars sur des ordinateurs bon marché qu’il fallait pouvoir rassembler pour l’analyse. C’était la nouvelle difficulté à résoudre. Des solutions transitoires ont été trouvées en attendant d’améliorer le transit des flux: Map Reduce et Hadoop. Ces deux software répandus à partir des années 2010 ont grandement facilité le traitement de données partagées mais étaient compliqués à intégrer dans les programmes. Les requêtes étaient plus faciles à conduire sur les entrepôts à l’ancienne.
Puis les clouds ont gagné en performance et aboli l’obstacle de la distance entre stockage et calcul. La course aux données engagée depuis 2005 s’est alors accélérée dans les années 2010. Les entreprises sentant la supériorité des Google et Facebook, ne voulaient pas être en reste et se sont mis à stocker des perabytes de données, juste au cas où…Les lacs de données sont devenus des marécages, Hadoop ne suivant plus le rythme de collecte de données non structurées. Maintenant que données et puissance de calcul sont de nouveau en phase, un nouveau blocage apparaît: l’analyse des données de masse du fait d’une insuffisance de données structurées.
Nouveau blocage…
Avec le déluge de données , les sociétés ont perdu la capacité de suivre et de mettre de l’ordre dans leurs données, comme elles le faisaient dans les entrepôts et les premiers lacs, aidés par Hadoop. L’organisation des services informatiques est devenue bicéphale: d’un côté les entrepôts avec leur données bien rangées, conformes et protégées traitées avec les programmes traditionnels en java, utilisés pour la stratégie. De l’autre les lacs de données devenus marécages, outils de travail des ingénieurs en intelligence artificielle programmant en pythons donnant libre cours à leur imagination pour concevoir leurs algorithmes. Comment faire communiquer ces deux mondes, éviter le gaspillage de données et avoir une vision unifiée de la stratégie pour débloquer le pouvoir de l’intelligence artificielle ? L’enjeu est d’importance. La mondialisation des années 90 a fait la fortune des grandes marques, des Coca Cola, Gillette et Procter & Gamble. La chute du mur a ouvert de nouveaux marchés mais l’intelligence économique a permis de les exploiter efficacement, de comprendre les spécificités locales tout en globalisant la logistique. Les années 2000 et 2010 ont vu l’écrasante domination de sociétés maîtrisant l’analyse de données de masse, Google d’abord puis Facebook, Amazon, Netflix, etc. Dans les années 2020, la robotisation de multiples tâches reposant sur des prédictions, peut propulser la productivité des entreprises qui sauront prendre la vague de l’IA. Pour cela, il leur faudra débloquer le verrou actuel, réconcilier le quantitatif et l’analytique.
La question à $100 milliards
Comment faire dialoguer les deux parties de l’entreprise: la partie analytique reposant sur un entrepôt trop exigu sur site, avatar du passé et la partie quantitative s’enfonçant dans un lac ou plutôt un marécage de données difficilement exploitables car n’étant pas estampillées par l’entreprise pour la sécurité et la conformité, ni ordonnées pour un objectif. Quand la direction générale parlera-t-elle aux développeurs ? Peu à peu, le centre de gravité passe de l’entrepôt (pour la direction générale) au lac de données (pour les développeurs), mais ce dernier n’est pas calibré pour l’analyse et la stratégie. De nouveaux concepts émergent pour réconcilier les deux points de vue, poussés par deux sociétés principalement, Snowflake et Databricks :
Snowflake est l’entrepôt version cloud, l’océan de données à l’échelle: plus efficace encore, il peut stocker des données structurées et semi-structurées, ce qui simplifie le travail de transformation initial. Les données sont donc stockées dans des entrepôts virtuels faciles à interroger pour les besoins stratégiques (analyses, intelligence économique, intelligence artificielle). Snowflake propose donc une capacité colossale de stockage et traitement en fonction des besoins, évitant les investissements coûteux sur site.
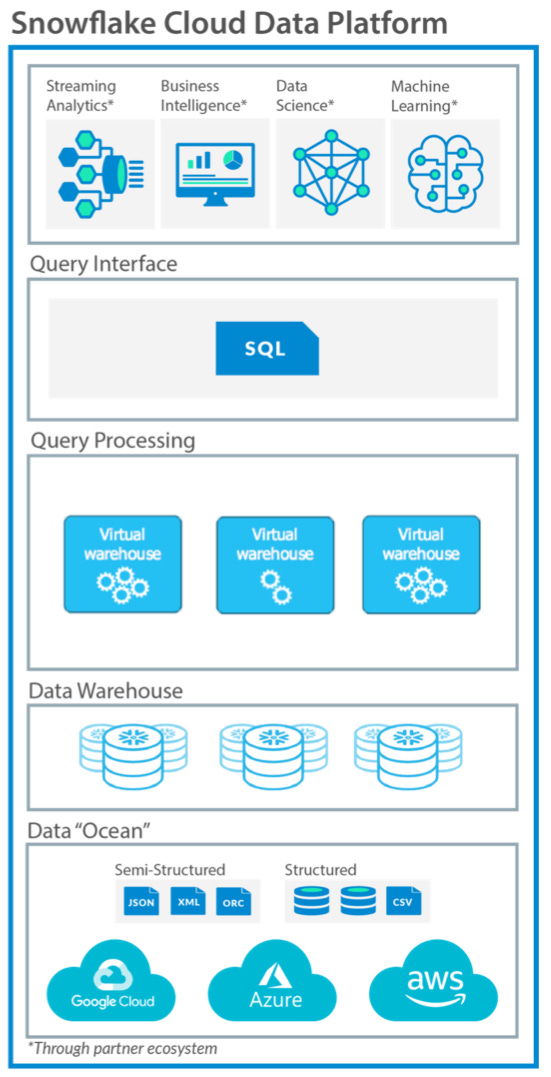
Snowflake a été introduit en bourse en septembre 2020, vaut $74 milliards pour un chiffre d’affaires annuel de $700 millions ! Les anticipations sont fortes…
Databricks, société non coté ayant misé sur l’open source, prend le parti non pas de l’entrepôt mais du lac de données où les données s’entassent structurées ou non un peu partout, en mode hybride. Sa valeur ajoutée initiale est de donner de la structure à ces données (il intervient donc en amont de Snowflake). Il s’appuie donc sur le lac de données de l’entreprise, réparti sur de multiples ordinateurs bon marché. Une fois les données structurées il traite les requêtes grâce à son moteur Apache Spark beaucoup plus rapide qu’Hadoop (il va chercher les données dans la mémoire et non dans les disques). Au final le lac de données peut être utilisé pour les besoins stratégiques (intelligence économique, intelligence artificielle, analyses).
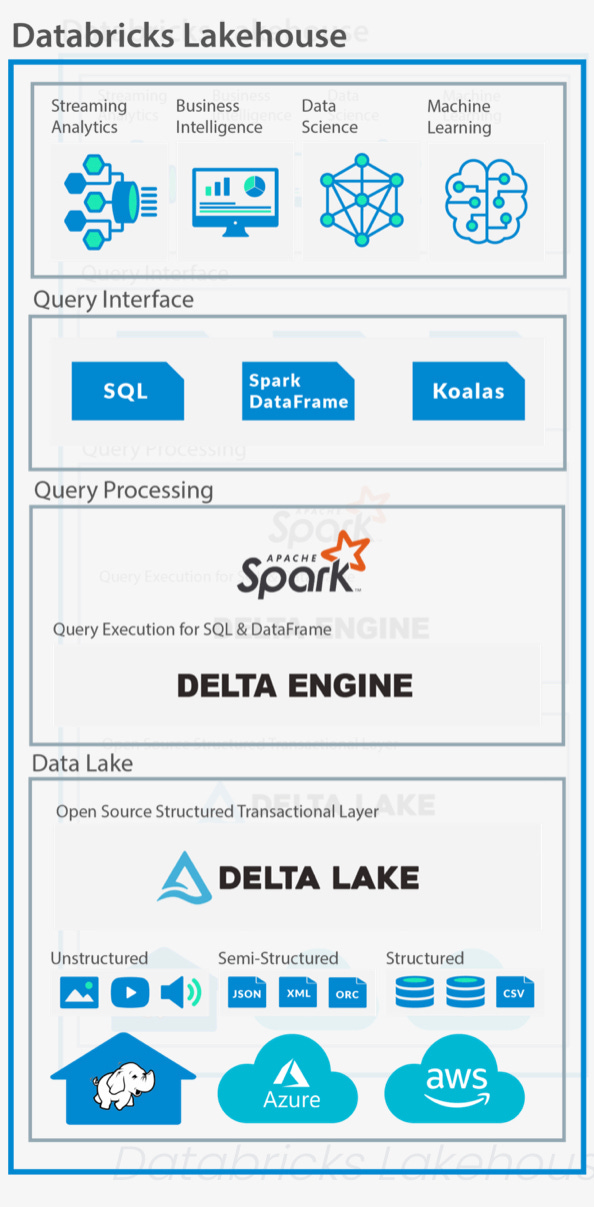
La question à $1 trillion
Si Snowflake et Databricks organisent la réconciliation entre les services informatiques des années 1990/2000 (logique entrepôt) et les ingénieurs en intelligence artificielle d’aujourd’hui (logique lac de données), la question essentielle reste de savoir comment structurer les données: pour prendre une image, savoir ce qu’on met dans les lignes et les colonnes du tableur. Snowflake fait un premier pas en transformant des données semi-structurées en données structurées. Databricks va plus loin avec Delta Lake en transformant des données non structurées. En amont, l’étape essentielle pour l’entreprise est de définir ses priorités et ses objectifs. Le lac de données nouvelle génération ne suffit pas si on ne lui donne pas un sens: quelles sont les données utiles pour la stratégie de l’entreprise ? Ali Ghodsi, fondateur de Databricks explique l’enjeu dans une interview pour Invest like the best:
Interviewer: Que doivent apporter les entreprises de leur côté ? Que doivent-elles apporter à la table pour commencer à travailler avec Databricks ? S'agit-il simplement d'un ensemble de données initial ? Comment envisagez-vous ce qu'une équipe, une personne ou un chercheur doit apporter pour que Databricks et sa plateforme deviennent puissants ?
Ali : Je pense qu'ils ont besoin d'ensembles de données, donc ils ont besoin de données réelles, que, heureusement, presque toutes les entreprises de la planète collectent depuis le milieu des années 2000. Et elles doivent avoir une compréhension claire des cas d'utilisation qu'elles veulent vraiment déployer ou réaliser. Pour cela, il faut qu'elles comprennent leur activité. Quel est le projet le plus important pour avoir un impact sur l'entreprise ? Quelle est la plus grande valeur commerciale à fournir ? Est-ce la prédiction de quelque chose ?
Pour une entreprise comme Shell, il s'agit de pouvoir prévoir à l'avance les pannes de ses équipements. Si elle peut le faire, elle peut alors remplacer ces pièces à l'avance, ce qui lui permet d'économiser des centaines de millions de dollars, et c'est en fait mieux pour la nature, pour les employés, pour l'environnement, etc. Pour une entreprise comme Comcast, c'est le cas d'utilisation où ils ont une télécommande et un bouton vocal, ils appuient dessus et ils peuvent parler dans la télécommande et dire, "Hey, quel est le temps aujourd'hui ?". Et puis cela s'actualise. Pour une entreprise pharmaceutique comme Regeneron, le cas d'utilisation consiste à trouver le gène particulier qui est responsable de la maladie. Par exemple, ils ont trouvé le gène responsable de la maladie chronique du foie dans Databricks. Ils peuvent ensuite effectuer des tests et développer des médicaments pour guérir ces maladies.
Il ne faut donc pas sous-estimer la compréhension de ces cas d'utilisation. S'ils se présentent en disant : "Hé, nous avons un tas de données et nous voulons faire des trucs cool, de l'IA", c'est généralement à ce moment-là que nous disons : "Eh bien, que veut-il vraiment faire ? Quels sont les cas d'utilisation qui sont vraiment pertinents pour votre entreprise ?"
C’est là où la technologie peut maintenant intervenir: aider les entreprises à définir leurs cas d’utilisation de manière plus systématique. Il leur faut répondre à la question: que faut-il prévoir ? Le marché potentiel est gigantesque et peut être pris d’assaut par des start up agiles. L’une d’entre elles est HASH, fondée par le développeur a l’origine de Stack Overflow, racheté récemment par Prosus. L’idée est de visualiser rapidement l’impact d’un programme d’intelligence artificielle à partir des données brutes de l’entreprise (non structurées). Cela permet de voir un résultat rapidement et de corriger le tir avant de lancer le lourd processus de raffinage, stockage et traitement des données. Voici l’annonce faite par Joël Spolsky dans son blog:
Avec David Wilkinson, je participe à la création de HASH. HASH permet de réaliser facilement de puissantes simulations et de prendre de meilleures décisions. En travaillant sur ce projet, nous avons découvert qu'une trop grande partie des données dont vous pourriez avoir besoin pour effectuer des simulations doivent être corrigées avant de pouvoir être utilisées. En effet, les données sont souvent publiées sur le Web à l'aide de langages de description de page qui s'intéressent davantage au formatage et à la consommation par les humains. Ces langages n'ont pas la structure nécessaire pour faciliter l'accès programmatique aux données qu'ils contiennent. La première étape consiste donc à effectuer une copie d'écran misérable et à nettoyer les données. C'est là que beaucoup de gens abandonnent.
Nous pensons avoir trouvé un moyen intéressant de résoudre ce problème. Si cela fonctionne, nous changerons le web aussi rapidement et complètement que Stack Overflow a changé la programmation. Mais c'est un peu ambitieux et peut-être un peu trop GRAND. Si vous souhaitez vous joindre à cette folle aventure, n'hésitez pas à nous contacter. Le tout sera open source, alors accrochez-vous, et nous aurons quelque chose sur GitHub avec lequel vous pourrez jouer.
HASH est un projet open source prometteur. C’est surtout une technologie disruptive susceptible de remettre à terme en cause à la fois les entrepôts de données et les lacs de données, donc leur aboutissement ultime, Snowflake à $74 milliards de dollars et Databricks à $28 milliards (105 fois et 62 fois le chiffre d’affaires respectivement). Il y a la de quoi débloquer le pouvoir de l’intelligence artificielle à peu de frais. Les prochaines années risquent d’être intéressantes…
Bonne fin de semaine,
Hervé