


Cloud version GPU
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.

Yahoo finances le 30 novembre 2023:
La conférence des développeurs AWS re:Invent d'Amazon (AMZN) a débuté cette semaine par une série d'annonces. Le premier enseignement à en tirer ? Amazon travaille fébrilement pour rattraper le leader de l'IA et son principal rival, Microsoft.
Re:Invent est la vitrine annuelle d'Amazon pour son importante activité Amazon Web Services. Cette année, l'entreprise a donné le coup d'envoi en mettant l'accent sur l'IA générative, afin de lutter contre la domination précoce de Microsoft (MSFT) et de Google (GOOG, GOOGL) sur le marché.
Les plus grandes annonces du salon comprennent le nouveau chatbot Q d'Amazon, une puce d'IA améliorée et un partenariat plus approfondi avec le puissant fabricant de puces Nvidia (NVDA). Chacune de ces annonces devrait aider Amazon, et son activité AWS, à rattraper les leaders du secteur.
Jusqu’à l’année dernière, le marché du cloud semblait bien installé entre les trois leaders, AWS, Azure et Google Cloud (65 % du marché environ), chacun avec leur stratégie respective et un effet d’échelle insurmontable. Quelques challengers comme Cloudflare, Oracle ou Salesforce par exemple essayaient de picorer quelques miettes en se spécialisant sur tel ou tel aspect (sécurité, base de données…). Leurs centres de données hébergeaient principalement des serveurs CPU (le CPU ou Central Processing Unit est une puce qui effectue des calculs selon une logique prédéterminée. Pour donner une image, c’est le cerveau logique de l’ordinateur, celui qui déduit).
Puis est apparu ChatGPT l’app géante qui pourrait dévorer toutes les autres (magasin GPTs), éliminer les outils de développement (grâce à GitHub Copilot) et s’appuyer sur une infrastructure GPU spécifique. Un GPU ou Graphic Processing Unit est une puce spécialisée dans des calculs massifs simples effectués en parallèle. Mis en batteries, les GPUs permettent d’entrainer ou de faire fonctionner des modèles d’IA. Pour donner une image, le GPU est le cerveau intuitif de l’ordinateur, celui qui induit. C’est pourquoi l’IA hallucine si souvent, malgré ses réponses bluffantes.
Les trois couches du cloud pourraient ainsi être remises en question par la généralisation de l’IA. Copilot remplacerait Windows. Que va-t-il rester du cloud ?
Le cloud version CPU
Le cloud paraît aujourd’hui bien structuré en trois couches distinctes comme présenté dans le tableau ci-dessous:

Cette structure fondée sur des CPUs Intel à 75% est l’aboutissement d’un développement erratique qui ne visait pas spécialement à créer une nouvelle industrie. La première avancée a été réalisée par Salesforce en 2000, qui a proposé un logiciel de gestion de la relation clients (CRM) en ligne sous forme d’abonnement. L’infrastructure et l’OS n’étaient pas visibles du client final, étant directement gérés par Salesforce. Salesforce était ainsi la première société SaaS. Les économies réalisées grâce à la mutualisation de l’infrastructure et de l’OS permettaient à Salesforce de proposer une offre plus attractive que le dominant de l’époque SAP et finalement de s’imposer. La performance boursière comparée des deux groupes depuis l’introduction de Salesforce est éloquente:

Amazon a bondi sur l’idée de Salesforce pour la généraliser. Pourquoi se limiter à mutualiser l’infrastructure et la couche middleware pour une seule application ? Amazon avait construit pour son propre e-commerce et ses commerçants partenaires une infrastructure de grande complexité, qualité, sobriété et rapidité. Sa logistique terrestre comme informatique n’avait pas d’égal. L’idée a alors germé dès 2002 de la proposer à des développeurs tiers. Il fallut encore quelques années pour que les premières grandes briques soient posées: Amazon S3 cloud storage et Elastic Compute Cloud en 2006 (stockage de données et calcul) puis les bases de données relationnelles et documentaires, etc. Parmi les premiers clients, on trouve SmugSmug, Pi Corporation…et Microsoft… Depuis, grâce à ses innovations permanentes dans les domaines Iaas et Paas, AWS est devenu de loin le premier opérateur cloud avec un chiffre d’affaires annuel de plus de $90 milliards.
Microsoft n’a réagi qu’en 2008 avec Windows, dont il espérait protéger le monopole, au cas où l’approche cloud l’emporterait. Il proposait donc une offre Paas (avec à la base Windows et ses langages compatibles) et une offre Saas (Excel, Word…) fonctionnant sur ses serveurs. Tout était Microsoft. Windows Azure était trop restrictif et limité pour les développeurs; il ne pouvait rivaliser avec AWS qui en proposant son infrastructure permettait à des développeurs de choisir leurs outils de développement, leur OS (Linux) beaucoup moins cher que Windows, leurs bases de données, etc. Nécessité faisant loi, Microsoft a dû progressivement abandonner son ancrage Windows et ce au prix du PDG Steve Ballmer. En 2014, Satya Nadella devient CEO de Microsoft. La même année, Windows Azure devient Microsoft Azure, un changement de nom symbolique marquant la volonté de ce cloud de se décentrer de Windows et de s’ouvrir à Linux et à l’open source. Azure opère un dégroupement de son offre entre Iaas, Paas et Saas, à la façon d’AWS. La différence est que l’offre Microsoft reste toujours plus facile à mettre en oeuvre sur Azure qu’une offre proposée par un développeur tiers. L’objectif est de faciliter le travail des entreprises, lesquelles n’ont pas forcément des cadors en informatique, non de concevoir des Rolls. Microsoft préfère vendre ses applications, son code et son infrastructure, fidèle à sa culture propriétaire. C’est pourquoi son véritable client est l’entreprise, pas le développeur.
Chacun son prisme: Google, en tant que moteur de recherche, est motivé pour qu’il y ait toujours plus de sites à indexer. Il crée donc App Engine (couche Paas) qu’il commercialise en 2010 à destination des développeurs de sites (une différence par rapport à Microsoft). Pluralsight, 8 juin 2023:
L'objectif d'App Engine était de faciliter le démarrage d'une nouvelle application web, puis faciliter son évolution lorsque cette application atteint le stade où elle reçoit un trafic important et compte des millions d'utilisateurs.
Google proposait alors, intégrée à son offre Paas, son infrastructure gigantesque pour héberger ces apps. Conformément à sa culture “d’indexateur pour compte de tiers”, Google cloud est devenu la plateforme d’apps tierces, celles qui se voyaient reléguées au deuxième plan par AWS et encore plus Microsoft. Astucieusement, il a développé le porte-container Kubernetes qui permet facilement de porter ses programmes d’un cloud à l’autre. En tant que numéro 3, il veut favoriser la migration vers son propre cloud. Google Cloud liste aujourd’hui 100 services Iaas, Paas et Saas disponibles pour les abonnés. Sa force est sa capacité de proposer l’abondance, sa faiblesse est le manque d’intégration, de lien entre les différentes facettes de son offre.
Les trois opérateurs cloud se rejoignent aujourd’hui sur les trois couches, même si chacun comme on l’a vu a ses forces et faiblesses. Ils dominent les quelques challengers qui se sont risqués à faire une offre mais qui sont impuissants à aligner une capacité hardware aussi économique (effets d’échelle/courbe d’expérience) et puissante.
L’attaque par la couche Saas
ChatGPT est sorti il y a un an et est devenu instantanément un produit de consommation. The Verge, 6 novembre 2023:
Après son lancement il y a près d'un an, ChatGPT a été largement considéré comme l'application internet grand public à la croissance la plus rapide de tous les temps, avec une estimation de 100 millions d'utilisateurs mensuels en seulement deux mois. Facebook, par exemple, a mis environ quatre ans et demi pour atteindre les 100 millions d'utilisateurs après son lancement en 2004, Twitter a mis plus de cinq ans et Instagram un peu plus de deux ans.
GitHub Copilot (un outil de génération de code par IA) avait été lancé plus d’un an plus tôt en juin 2021 par Microsoft en collaboration avec OpenAI. Ce produit a connu un certain succès auprès des développeurs (couche Paas), il compte aujourd’hui 1 million de membres. Le buzz n’a, ceci précisé, rien à voir avec celui créé par ChatGPT. Microsoft s’est saisi du buzz de ce dernier pour en lancer sa propre version (Bing Chat devenu Copilot). Dès lors Microsoft a deux fers au feu qui viennent renforcer sensiblement son offre cloud: ChatGPT, produit à destination du consommateur particulier et Copilot à destination des entreprises. Microsoft n’est pas bon sur le consommateur et délègue à ChatGPT (il détient 49 % d’OpenAI). En revanche, il se garde la partie entreprise, son point fort. Cela lui permet d’avoir deux applications fortes liées à son cloud Azure. Dès lors Microsoft, fort de l’avance des modèles LLMs d’OpenAI proclame les bénéfices de leur intégration avec son propre cloud, se différenciant clairement de la modularité d’AWS et encore plus de Google Cloud. Satya Nadella, lors de la conférence sur les résultats du trimestre dernier:
Il est vrai que l'approche que nous avons adoptée est une approche complète, qu'il s'agisse de ChatGPT, de Bing Chat ou de tous nos copilotes, tous partagent le même modèle. Dans un certain sens, l'une des choses que nous avons, c'est un très, très grand effet de levier du modèle que nous avons utilisé, que nous avons formé, et ensuite du modèle que nous utilisons pour l'inférence à l'échelle. Et cet avantage se répercute sur l'utilisation en interne, sur l'utilisation par des tiers, et au fil du temps, vous pouvez voir l'optimisation de la pile jusqu'au silicium, parce que la couche d'abstraction à laquelle les développeurs accèdent est beaucoup plus élevée que les noyaux de bas niveau, si l'on veut.
Je pense donc qu'il y a une approche fondamentale que nous avons adoptée, qui était une approche technique consistant à dire que nous aurons des copilotes et une pile de copilotes disponibles. Cela ne veut pas dire que nous n'avons pas de personnes qui font de la formation pour des modèles open source ou des modèles propriétaires. Nous disposons également d'un certain nombre de modèles open source. Nous disposons d'un grand nombre d'ajustements, d'un grand nombre de RLHF. Il y a donc toutes sortes d'utilisations possibles. Mais le fait est que nous avons un effet de levier à l'échelle d'un grand modèle qui a été formé et d'un grand modèle qui est utilisé pour l'inférence dans toutes nos applications SaaS de première partie, ainsi que dans notre API dans notre service Azure AI....
La leçon tirée du cloud est que nous ne dirigeons pas un conglomérat d'entreprises différentes, il s'agit d'une seule et même technologie dans l'ensemble du portefeuille de Microsoft, et je pense que cela sera très important parce que cette discipline, étant donné ce à quoi ressemblent - ressembleront les dépenses pour cette transition vers l'IA, toute entreprise qui n'est pas disciplinée quant à ses dépenses d'investissement dans l'ensemble de ses activités pourrait avoir des problèmes.
Microsoft Azure plus que jamais devient un monolithe, intégrant ChatGPT (Copilot) et son Iaas à base de GPUs. La logique du cloud à trois couches telle que conçue par Aws devient progressivement sans objet.

Il est clair que pour Microsoft, l’IA générative n’est pas une mode, puisque Copilot est censé remplacer Windows !
Le cloud modulaire
AWS et Google Cloud, en opposition à Microsoft jouent à fond la carte du cloud modulaire. Leurs clients sont les développeurs, la raison d’être du cloud à l’origine. C’est donc par la couche Paas, sacrifiée par Microsoft qu’ils vont attaquer. Les déboires récents au sein du conseil d’administration d’OpenAI ont montré la précarité de développer ses programmes sur un substrat GPT. Quid de la continuité du LLM, dans le cas où le conseil d’administration, mû par des considérations autres que financières et concurrentielles décide d’arrêter ? Rien n’illustre mieux ce risque que les développements récents chez Perplexity AI, un moteur de recherche à base d’IA générative. Perplexity a commencé à proposer un moteur de recherche propulsé par GPT, donc par Azure. Il réalise maintenant que l’IA “passe partout” n’est pas forcément la bonne option pour tous les usages, en particulier dans son cas pour la recherche. GPT-4 par exemple est très sollicité et les réponses par conséquent trainent en longueur, ce qui ne convient pas quand on a Google en face. Perplexity expérimente donc deux LLMs au nombre de paramètres limités optimisés pour la recherche, un créé par le français Mistral AI (7 milliards de paramètres)et l’autre par Meta (70 milliards de paramètres). Pour mémoire GPT-4 affiche 1760 milliards de paramètres…Ces deux modèles fonctionnent sur le cloud AWS et sont nettement plus économiques que GPT pour Perplexity AI. Le compromis performance/coût est en faveur de ces deux modèles, donc en faveur en l’occurence du cloud AWS. Et s’ils sont plus performants sur des domaines spécialisés, ils seront adoptés à la place de ChatGPT.
Le pari d’AWS et de Google par opposition à Microsoft est de faire valoir plusieurs offres de LLMs en laissant aux développeurs le plus large choix possible pour développer autour de ses LLMs:
Amazon reste le “Everything Store” décrit par Brad Stone. Les développeurs d’IA générative peuvent utiliser SageMaker et gérer l’entrainement des modèles sur infrastructure AWS (puces Nvidia ou Trainium moins chères). Ils peuvent aussi se contenter d’Amazon Bedrock et utiliser les modèles tels que Llama ou Anthropic, voire le modèle Q propriétaire, la couche infrastructure étant gérée par AWS. Amazon vise le maximum de possibilités et de souplesse.
Google est tiraillé entre son souhait d’imposer son LLM propriétaire très puissant Gemini, pour devancer AWS et sa volonté de proposer une approche modulaire pour devancer Microsoft. En tant que numéro 3, il doit être meilleur. Le point fort de Google Cloud est la couche Paas, à l’origine App Engine pour les applications web, et maintenant Vertex AI pour l’intégration d’IA générative dans ces mêmes applications. Vertex AI abstrait la couche infrastructure, gérée par Google et propose aux développeurs différents LLMs “as a service” (dont Llama de Meta) qu’ils peuvent enrichir de leurs données et utiliser pour doper leurs applications. Parmi ceux-ci, le privilégié est Gemini qui est sorti le 6 décembre en trois versions: Gemini nano pour les développeurs d’apps mobiles, Gemini Pro pour les développeurs et entreprises lambda, enfin Gemini Ultra capable de naviguer 57 sujets, dont maths, physique, histoire, droit, médecine, etc. Google ne précise pas si Gemini Ultra sera proposé pour les développeurs, mentionnant surtout son intégration prochaine dans Bard (clause de la nation la plus favorisées).
Un cloud GPU ?
Il y a cependant un point commun entre les trois clouds: ils ont conclu l’un après l’autre un accord avec NVIDIA pour héberger DGX Cloud. DGX Cloud est un ensemble de serveurs appartenant à Nvidia de grande puissance parfaitement calibrés (hardware et software) pour entrainer des modèles d’IA générative de masse. Ces serveurs sont proposés à la location par Nvidia aux développeurs à travers les services cloud d’AWS, Azure et Google Cloud. L’intérêt de Nvidia est de bénéficier:
de la force de distribution des trois opérateurs, voire quatre puisqu’Oracle a été le premier à tirer.
de la capacité des trois opérateurs à gérer un cloud (sécurité, gestion de la capacité, économies d’énergie, inférence des modèles IA, etc.)
de l’intégration avec les trois couches gérées par les opérateurs cloud. L’intelligence inductive se lie à l’intelligence déductive.
L’intérêt des opérateurs cloud est moins évident: pourquoi n’intègrent-t-ils pas directement les puces Nvidia dans leurs serveurs ? J’y vois deux raisons principales:
Les serveurs Nvidia sont “GPU d’abord” alors que les serveurs des opérateurs cloud sont en général “CPU d’abord”. Ils sont donc plus performants pour les tâches d’entraînement. Un serveur “GPU d’abord” comprend 8 CPUs pour 1 GPU; un serveur “CPU d’abord contient 128 CPUs pour 1 GPU” (source SemiAnalysis).
Ne pas signer avec Nvidia fait courir le risque de passer en second rang pour l’achat à l’échelle de ses puces les plus performantes. Cette raison est probablement la plus importante. Les opérateurs traditionnels ne veulent pas aujourd’hui être à court de puces Nvidia de dernière génération.
En résumé, Nvidia étant le seul producteur aujourd’hui de puces ultra-performantes pour l’entrainement des modèles, il exerce un levier sur les opérateurs cloud qui doivent accepter d’héberger son cloud.
Poussé au bout de la logique, le cloud ne devient-il pas GPU, les opérateurs existants étant freinés par le poids du passé, les serveurs CPU ? Ne pourrait-on pas appliquer au cloud la logique du dilemme de l’innovateur théorisé par Clayton Christensen ? Selon GPT-4:
Le "dilemme de l'innovateur", théorisé par Clayton Christensen, est un concept essentiel dans le domaine de la gestion de l'innovation et de la stratégie d'entreprise. Il décrit le défi auquel sont confrontées les entreprises établies lorsqu'elles doivent gérer des innovations de rupture qui menacent de déstabiliser leur modèle d'affaires existant.
Selon Christensen, les entreprises prospères peuvent être tellement concentrées sur les besoins actuels de leurs clients et sur l'amélioration continue de leurs produits qu'elles négligent ou sous-estiment les innovations de rupture. Ces innovations de rupture, souvent initiées par de nouveaux venus dans l'industrie, ne répondent pas initialement aux standards du marché dominant et peuvent donc être perçues comme inférieures. Cependant, elles s'améliorent rapidement et peuvent finalement dépasser les besoins des clients du marché principal, laissant les entreprises établies en difficulté.
Le dilemme réside dans le fait que les actions qui sont les meilleures pour la santé actuelle d'une entreprise (comme écouter les clients existants, se concentrer sur les marges de profit et améliorer les technologies existantes) peuvent être précisément celles qui mènent à son échec face à des innovations de rupture.
La solution au dilemme de l'innovateur n'est pas simple. Elle implique souvent que les entreprises établies doivent reconnaître et investir dans les nouvelles technologies, même si cela signifie cannibaliser leurs produits existants ou remettre en question leurs pratiques commerciales actuelles.
Ici, les cloud GPU partiraient à l’assaut des cloud CPU existants, la charge d’entrainement des modèles devenant la priorité informatique numéro 1. Ils ne seraient pas très performants sur les taches généralistes au départ mais s’amélioreraient progressivement au niveau suffisant pour mettre les opérateurs cloud traditionnels en difficulté et en infériorité sur la partie GPU. Ce scénario me parait improbable. Les cloud GPU sont en effet très simple à opérer (taches répétitives) avec une partie logicielle limitée. Leur seul atout est d’avoir des GPUs Nvidia, leur avantage concurrentiel étant leur relation de proximité avec Nvidia. En dehors de cela, les clouds GPU sont essentiellement une affaire de capitaux investis: d’après SemiAnalysis, voici les coûts respectif d’un serveur CPU et d’un cloud GPU:
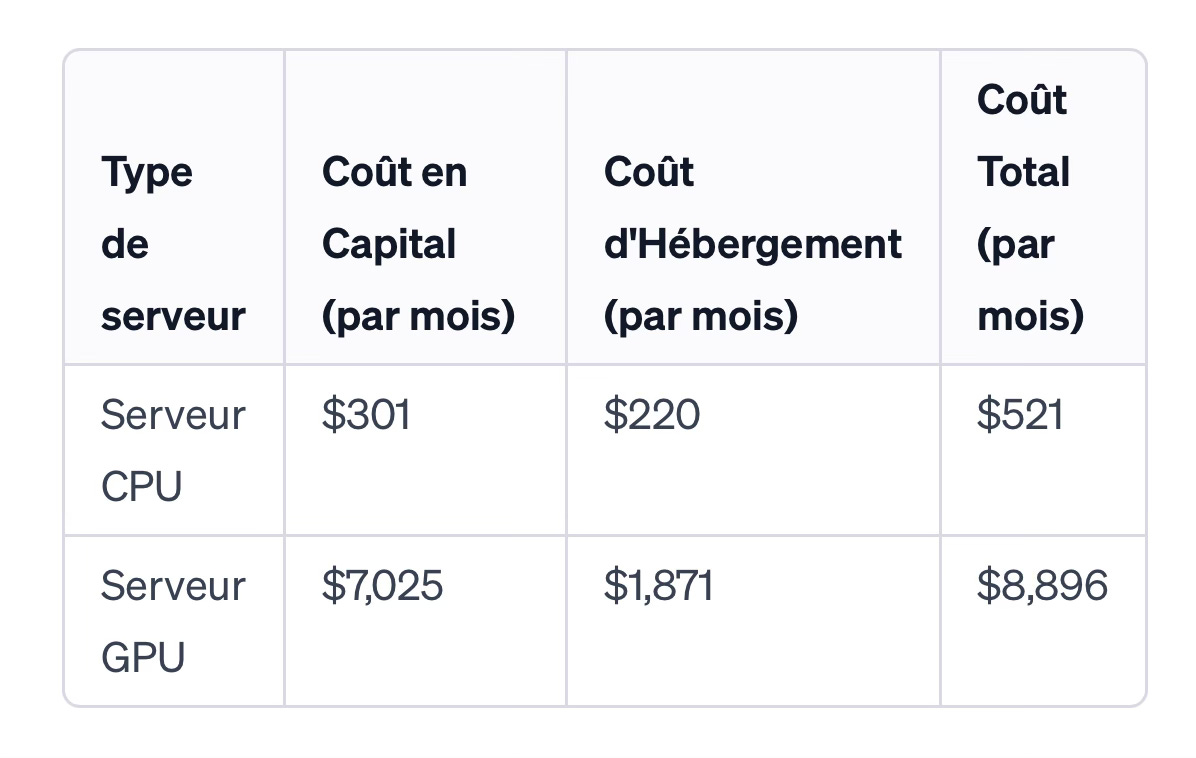
D‘un côté (serveur GPU): simple mais cher, de l’autre (serveur CPU) bon marché mais complexe à opérer. Il n’est donc pas étonnant que les clouds GPU pullulent car ils trouvent aujourd’hui des capitaux faciles, effet de mode aidant. Leur manque de différenciation causera leur perte:
Les opérateurs cloud traditionnels peuvent plus facilement que les nouveaux venus absorber de tels investissements amortis sur leur masse de clients. Ils peuvent combiner serveurs CPU et serveurs GPU, logique et induction pour une intelligence supérieure.
Tout en achetant des puces Nvidia et en hébergeant DGX Cloud, ils songent déjà à leur remplacement par leurs propres puce moins onéreuses (Trainium pour Amazon, Maia pour Azure) qui réduiront sensiblement le coût de leurs propres serveurs GPU. Dès lors leurs clients pourront entrainer leurs propres modèles à des coûts moins élevés que les clous GPU.
Enfin les cloud traditionnels peuvent déjà égaler, voire dépasser Nvidia sur les puces d’inférence qui permettent aux IA de générer les réponses aux prompts (peut-être 80 % du marché). C’est le cas de Google qui vient de sortir la version 5 de sa puce d’inférence TPU et qui en la couplant avec une puce Nvidia pour l’entrainement proposé à ses clients une combinaison difficile à égaler.
Y-a-t-il un risque que Microsoft et Nvidia reconstituent l’ancien duopole des années 90, le fameux couple Wintel (Microsoft+Intel) ? Le scénario serait le suivant: GPT alimenté par les puces Nvidia, proposé par Microsoft sous sa version Copilot devient dominant grâce à la qualité du LLM sous-jacent d’OpenAI. Microsoft en fait le centre de l’univers Saas (chaque application devient un plug in de Copilot) et abstrait les couches Paas et Iaas: il rend le cloud obsolète en formant un tout monolithe au service des applications Saas.
Ce scénario semble bien improbable:
Les sociétés informatiques ont appris des années 90 la nécessité de proposer rapidement des alternatives au monolithe Microsoft: c’est ce qu’elles font aujourd’hui avec la perspective d’avoirs des produits certes moins intégrés mais moins cher et de meilleure qualité.
ChatGPT n’est pas une IA générale qui rend obsolète les autres modèles de fondation: il y a plusieurs modèles possibles en fonction des besoins et des spécificités. Des modèles avec moins de paramètres et plus spécialisés peuvent être plus performants à moindre coût que ChatGPT.
Le risque de dépendre d’un seul modèle est trop grand, comme l’ont montré les péripéties autour du conseil d’administration d’OpenAI.
Dès lors, l’intelligence logique et l'intelligence inductive, les CPUs et GPUs se complèteront au sein de centres de données encore plus massifs et complexes à gérer. Les trois clouds continueront leur jeu d’équilibre des forces avec probablement un avantage supplémentaire par rapport à leurs challengers: les économies d’échelles sont encore plus nécessaires en mode GPU…
bonne semaine,
Hervé