


La montée en puissance des IA spécialisées
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
Ce graphique illustre parfaitement le phénomène :
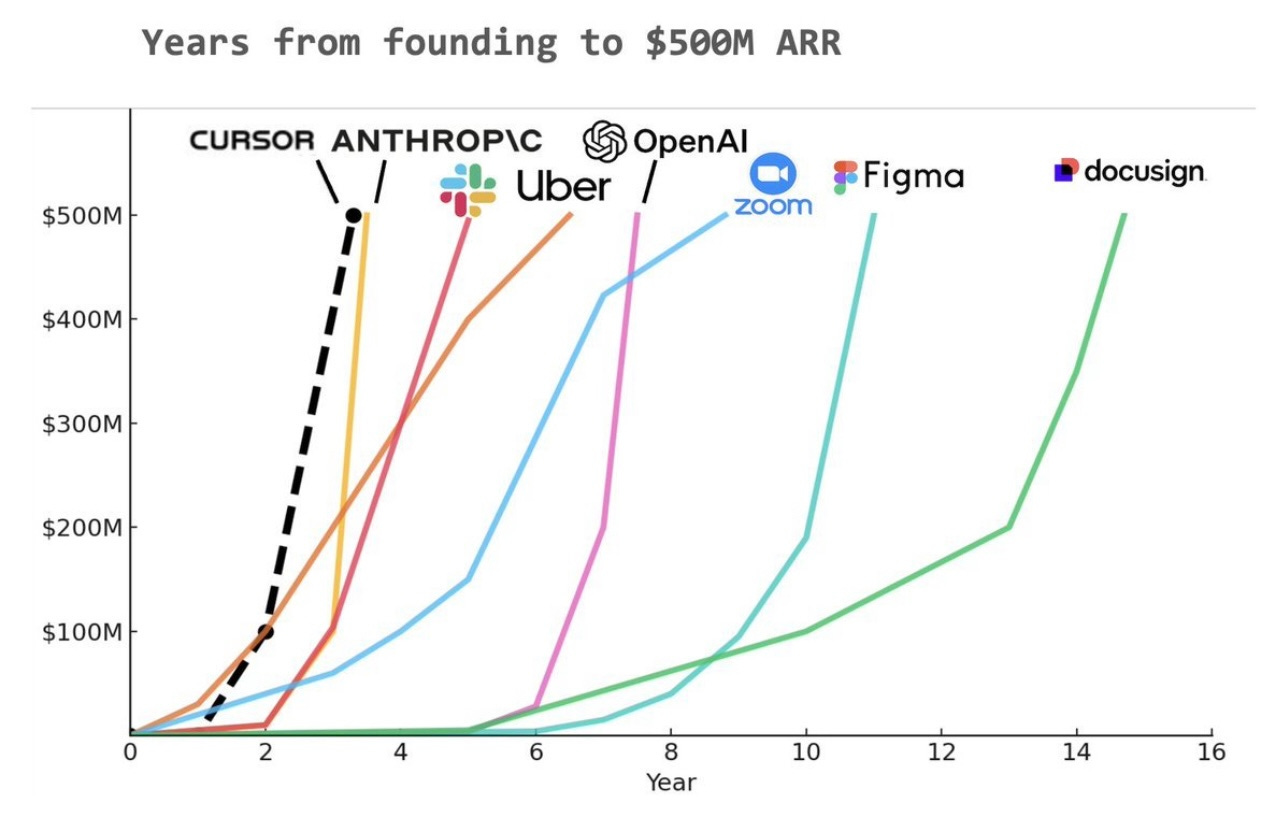
L’attention tant du public que des professionnels de la tech porte sur les modèles généralistes de dernière génération comme ChatGPT, Claude, Llama ou DeepSeek. OpenAI par exemple vient de franchir la barre de $10 milliards de chiffre d’affaires annualisé, plus du double de l’année précédente tandis que Meta AI a franchi le milliard d’utilisateurs. La quête de l’IA générale ou super-humaine est ce qui motive les grandes sociétés tech comme Amazon, Meta, Microsoft ou Google, elles sont prêtes à investir des centaines de milliards de dollars pour y parvenir. Le public suit, chaque nouvelle version d’un modèle éclipse la précédente, le progrès est tangible, on perçoit l’arrivée de l’intelligence artificielle générale. Il y a une réelle pénurie de capacité tant en entraînement qu’en inférence: tout le monde y croit et l’anticipe.
Pourtant, le cas de Cursor montre qu’une IA spécialisée, à objectif plus limité peut causer autant d’engouement qu’un modèle généraliste à tout faire, voire d’avantage ! En moins de trois ans, Cursor génère $500 millions de revenu annuel, battant ChatGPT, Anthropic ou bien d’autres start-up à succès en terme de rythme de croissance. Cursor bat le record mondial de croissance champignon. Cependant cette croissance est moins exceptionnelle si on la considère en nombre d’utilisateurs car là ChatGPT fait la course en tête de loin, laissant Cursor dans le peloton:
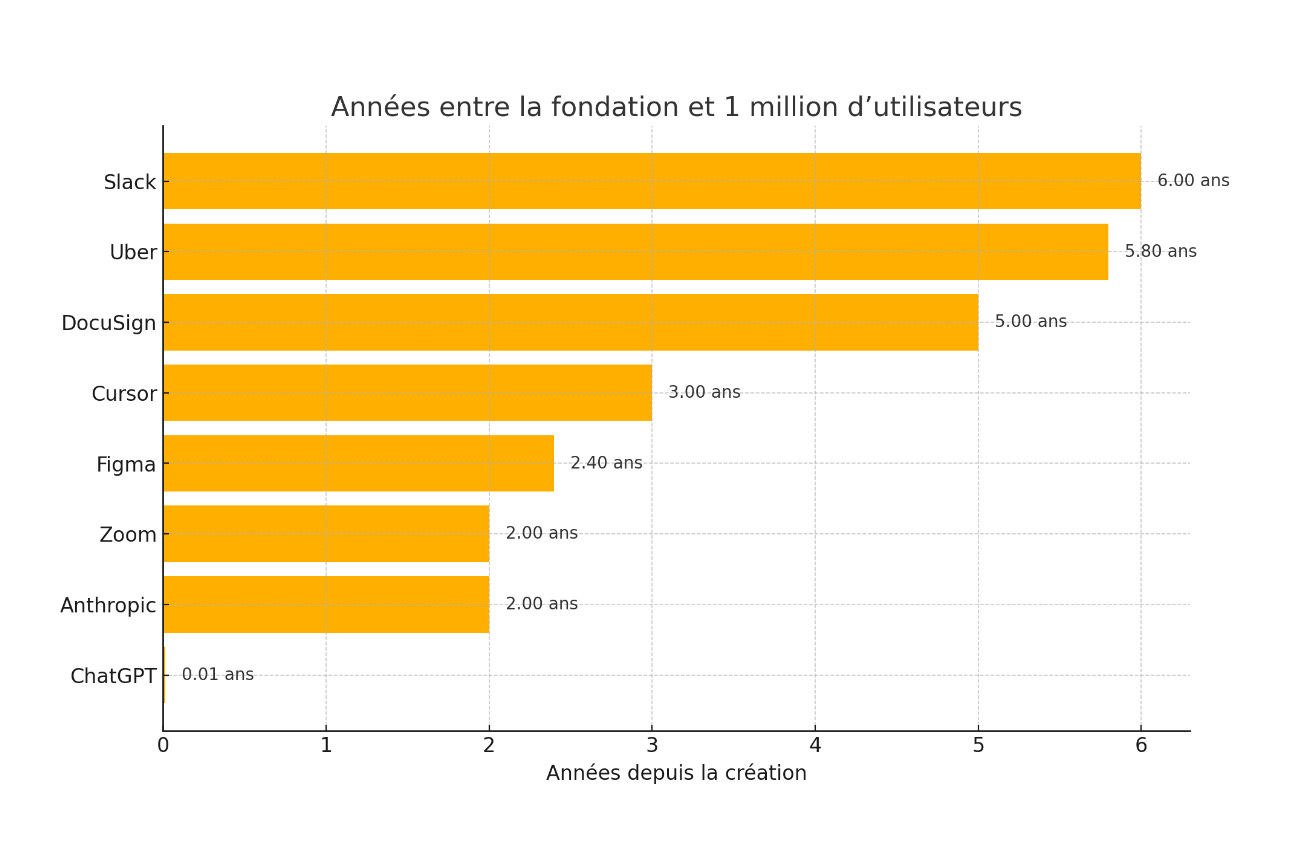
La différence par rapport à une IA généraliste type ChatGPT est que les utilisateurs sont d’avantage enclins à payer pour Cursor, manifestant ainsi la vitalité de ce modèle économique. Intéressons nous maintenant à Cursor pour comprendre cet engouement pour une IA spécialisée, si cet engouement peut durer, avec quel objectif et potentiel à long terme. Enfin le cas de Cursor peut il être transposé à d’autres métiers ? Ce sont des questions à plusieurs trillions de dollars.
Cursor

Cursor est un éditeur de code, un environnement logiciel conçu pour créer, consulter et modifier du code-source (comme Word mais pour le code). Le succès de Cursor met en question la théorie selon laquelle on n’aura bientôt plus besoin de coder ! La réalité est peut-être plus pragmatique. Creusons un peu.
Petit historique de l’édition de code
Dans les années 50, programmer consistait à perforer des cartes qu’on compilait (rassemblait) pour insertion dans la machine et exécution. Puis le code est devenu du texte (langage de programmation) et le compilateur (traduction du code en langage machine) un programme. L’éditeur était le réceptacle du code. Dans les premiers temps (années 60), l’édition se faisait sur papier et non sur écran ! Dans les années 70, un progrès notable a été l’édition sur écran. Elle permettait plus de rapidité et d’interactivité dans la rédaction du code, grâce à l’intégration progressive de l’édition, de la compilation et du déboggage. L’édition devient environnement de développement intégré (IDE): on code, on voit ce que ça donne et on corrige les bugs (fin des années 80, années 90). En 2015, une étape est franchie avec le lancement de Visual Studio Code par Microsoft. VS Code est un environnement de développement intégré open source qui est devenu la référence pour l’écriture du code. La stratégie de Satya Nadella était simple: offrir un éditeur gratuit multiplateforme (Windows, Linux ou MacOS), fonctionnant parfaitement avec Azure: VS Code était un pilier du pivot stratégique de Microsoft de Windows vers le cloud. 75% des développements se sont faits sur VS Code en 2024. C’est une des réussites de Satya Nadella.
L’intégration de l’IA
Depuis le début des années 1980, les éditeurs de code essaient de faciliter le travail du codeur en lui suggérant le prolongement de son code. C’est ce qu’on appelle l’auto-complétion:
Elle était au départ extrêmement limitée aux fonctions préalablement définies qui pouvaient être suggérées à nouveau quand le codeur inscrivait le début du nom de la fonction. L’auto-complétion permettait également de finir un mot en fonction de la première lettre: suggérer « print » quand on commençait à taper « pr ».
Avec l’introduction des LLMs, l’auto-complétion devient plus systématique, quoiqu’encore limitée. Cette fois le LLM propose des blocs de code standard, soit fonction du contexte (ce que le codeur a déjà réalisé), soit sur requête spécifique. GitHub Copilot branché nativement à VS Code fait ainsi des suggestions pour aider le développeur. La stratégie de Microsoft est toujours la même: créer des fonctions qui amènent les codeurs à travailler sur Azure. VS Code et GitHub Copilot sont des compléments d’Azure. GitHub Copilot a rencontré un vif succès puisque son chiffre d’affaire annualisé est de plus de $400 millions après 4 ans d’existence.
Cette logique a ses limites. Microsoft, tout en prônant l’open source, cherche à entraîner les codeurs dans son univers, leur faisant apprécier la superposition facile de ses différents outils (l’éditeur, l’intelligence artificielle, le cloud). Avec Microsoft tout s’emboîte même si chaque bloc n’est pas forcément le meilleur, l’important étant qu’il soit stable. Certains codeurs (des passionnés) pensent que la superposition n’est pas suffisante. Il faut que l’IA imprègne plus profondément, à sa racine, l’éditeur, le fasse évoluer, pour démultiplier ses capacités et coder de plus en plus à la place du codeur. Cursor a ainsi été créé par trois développeurs, anciens du MIT, ayant pour objectif ultime de remplacer le codeur. Cependant , il ne faut pas confondre la direction et les étapes nécessaires pour parvenir à un objectif lointain. La première étape, qui est celle d’aujourd’hui, est de comprendre l’intégralité du contexte (tout le code existant) pour aider opportunément. Cursor a été pensé dans cet objectif, ce qui a nécessité de faire une fourche sur VS Code. C’est contraignant au départ pour le codeur qui doit abandonner son éditeur préféré pour en choisir un autre légèrement différent. En revanche l’aide apportée est bien plus significative que celle de GitHub. L’auto-complétion est plus précise, opportune et globale (rédaction d’importants blocs de code, correction de bugs, insertion de code dans de multiples fichiers simultanément…)
La stratégie Cursor
L’idée fondamentale de Cursor est de comprendre le codeur pour le servir. Le présupposé est que le codeur restera indispensable encore pendant de nombreuses années pour créer la logique et superviser le code. Pour son fondateur, nous sommes encore à des années lumières du « vibe coding », c’est à dire du code complet fonction d’un prompt. Le graphe suivant montre la dégradation exponentielle de la qualité du code fonction du temps de codage automatique :
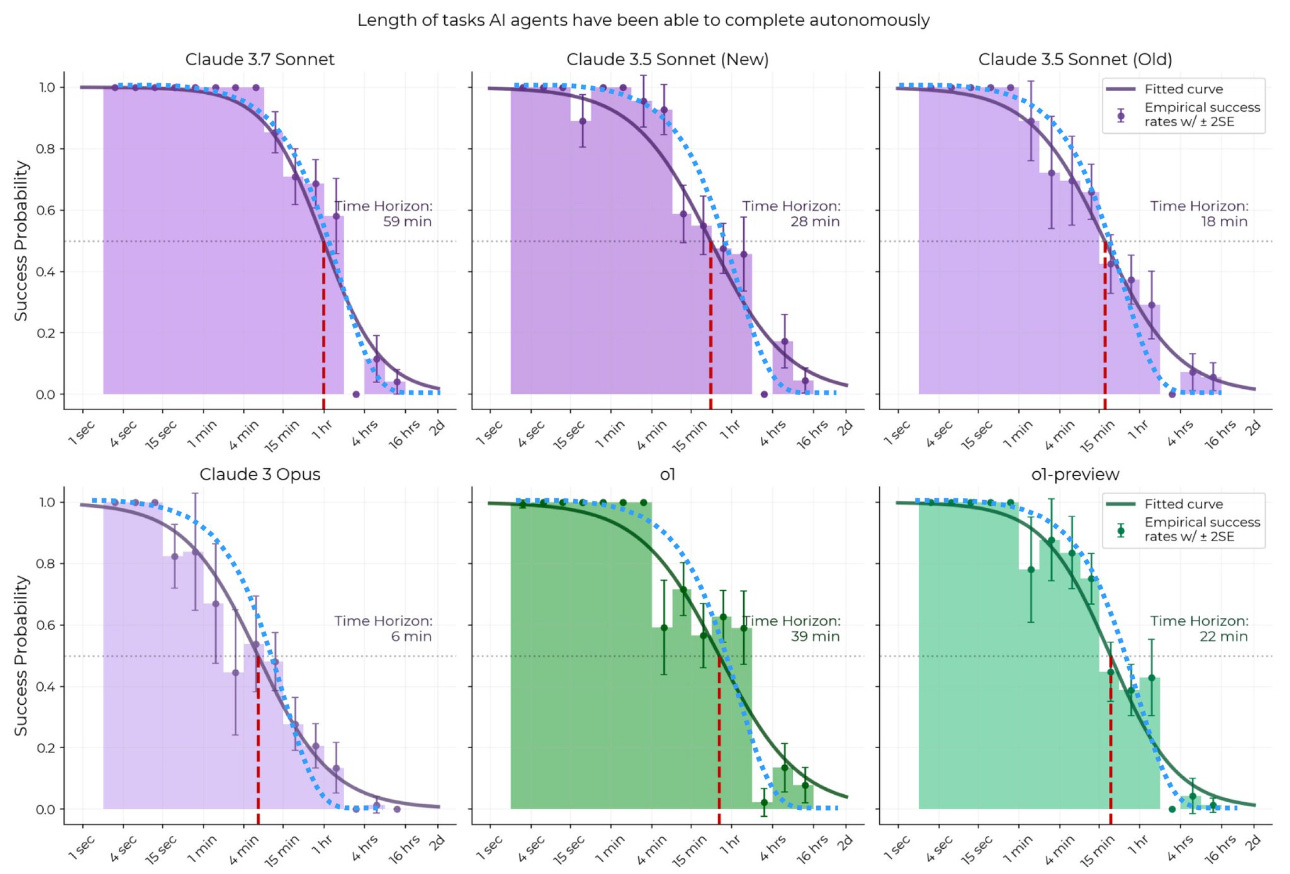
Normal: le taux d’erreur se compose avec le temps. En attendant, le rôle de Cursor est de mâcher le travail du codeur toujours plus. Microsoft est trop statique, servant les intérêts d’Azure et ChatGPT veut remplacer trop tôt le codeur. Il y a de la place entre les deux. Pour comprendre les codeurs, il faut les données sur ce qu’ils font et adopter une logique d’apprentissage par renforcement, pour améliorer l’éditeur. C’est pourquoi en plus de proposer un branchement à ChatGPT ou Claude, Cursor fabrique ses propres modèles hyper-spécialisés alimentés par les données de ses codeurs. C’est un élément de différenciation majeur pour Cursor:
-les modèles peuvent faire de l’auto-complétion très rapide et adaptée;
-il ne sont pas avares en token produits car ces derniers sont beaucoup moins chers que ceux des grands LLMs généralistes, d’où la génération de blocs de code importants; Cursor peut déjà compléter 5 à 10 minutes de code.
-ils peuvent également servir d’interprète des grands LLMs pour plus d’efficacité.
-enfin ils nourrissent la machine à données.
En fait Cursor se rapproche du Google des années 2000 qui se différenciait grâce aux données de ses utilisateurs et devenait de plus en plus pertinent par rapport aux moteurs de recherche existants. Dans cette logique, Cursor peut servir le développeur pendant de nombreuses années encore, affinant ses réponses au fur et à mesure. Plus il sera adopté par les développeurs, plus il s’enrichira de leurs données, plus il deviendra performant et plus les LLMs souhaiteront passer par lui pour les atteindre. Alors que les grands LLMs cherchent à faire disparaître le codeur (fonction Canvas), Cursor cherche simplement à banaliser ces grands LLMs pour avancer pas à pas dans l’automatisation.
Les prochaines étapes
Il faut bien comprendre que construire du code est un processus très complexe qui doit être fait au plus près de la machine, demande une gestion très stricte des contraintes sur des fichiers multiples. La simplicité du résultat masque la complexité du programme. Pour Michael Truell, fondateur de Cursor, bâtir un programme est aussi complexe que construire une fusée. Beaucoup de gens ne le comprennent pas, s’imaginant que Canvas (ChatGPT ou Gemini) va faire le travail en autonome. C’est toute l’opportunité pour une entreprise qui comprend l’importance de l’enjeu.
Aujourd’hui environ 10% du code peut être pris en charge par l’IA. Dans les 6 à 12 mois, Michael Truell pense pouvoir faire passer le ratio à 20/25%, des portions toujours plus importantes du code pouvant être prises en charge par des agents IA. Cette phase reste encore de l’auto-complétion, mais plus poussée.
Il restera à ce stade 75/80% à remplacer ! Il faudra alors s’attaquer à la logique proprement dite. Le modèle local aura tout le contexte du code et pourra coder comme son maître au plus près de la machine, inventant au besoin une logique fonction du contexte.
Enfin un prompt suffira pour avoir un programme.
On peut récapituler dans un tableau les différents niveaux d’automatisation (nous sommes aujourd’hui au niveau 2/3 et le temps sera long pour arriver au niveau 5):

Il y a donc un boulevard de progrès à réaliser avant d’arriver au niveau 5 et c’est ce qu’entreprennent des firmes comme GitHub Copilot (avec ses contraintes), Cursor ou Windsurf (racheté par OpenAI). Le marché potentiel est très large, le code professionnel imprégnant une part de plus en plus substantielle de l’économie. Cependant l’approche Cursor intégrant l’intelligence artificielle plaît d’avantage aux codeurs que l’approche Github Copilot la superposant :
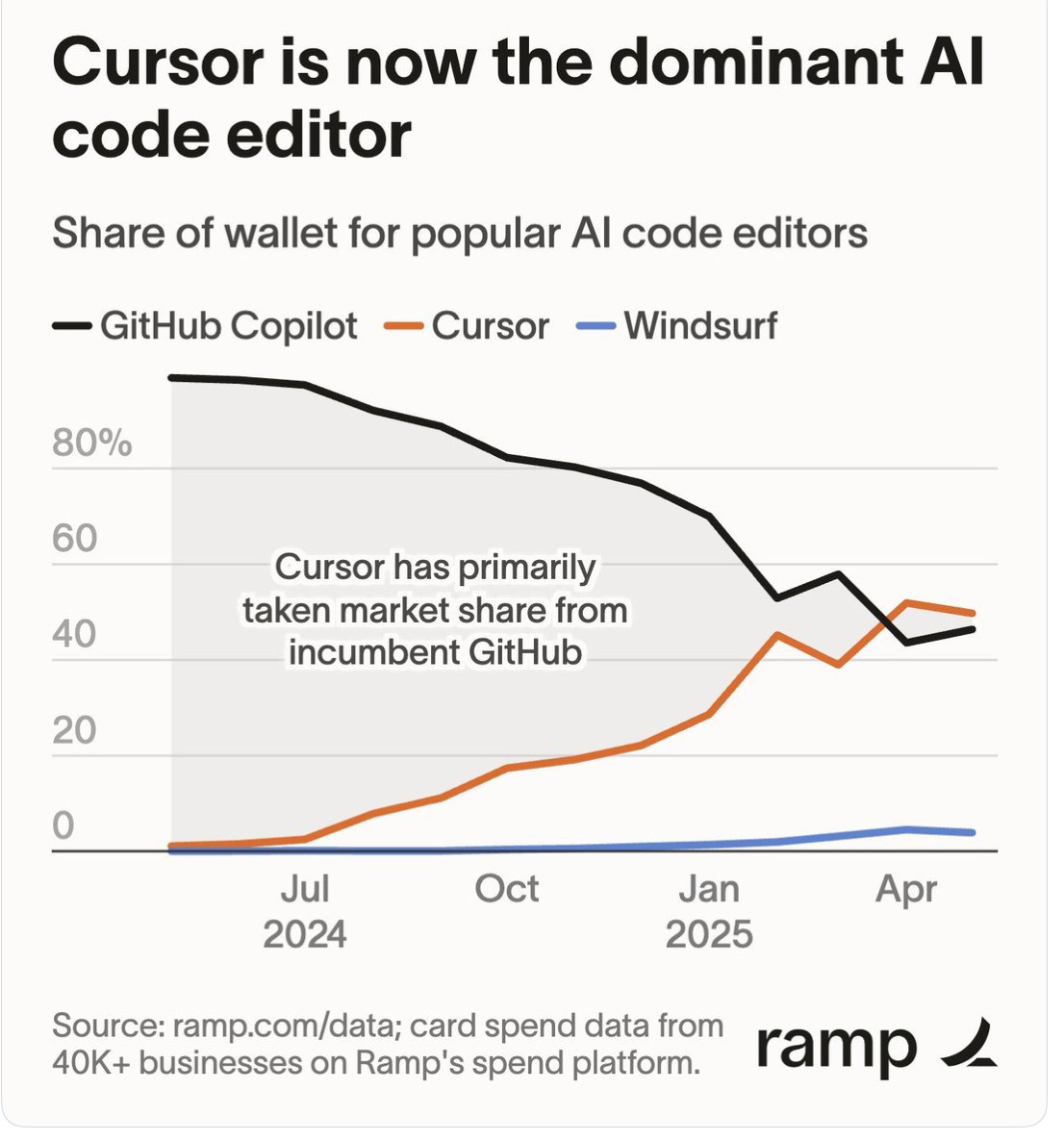
Avec le temps, le codeur va devenir de plus en plus haut de gamme, se concentrant sur la logique et laissant à l’IA tout le répétitif. Cette montée en puissance n’est pas sans rappeler une autre IA spécialisée : celle qui va piloter nos voitures et qui constitue aussi un marché énorme.
Le parallèle avec les voitures autonomes
Il y a là aussi un décalage entre le fantasme des voitures sans chauffeurs inondant le marché (fantasme alimenté par Elon Musk) et la réalité plus prosaïque de la nécessité d’un contrôle humain. C’est dans ce milieu que réside l’opportunité. L’IA oblige à tout reconstruire mais le pragmatisme est la clé. Ci après les différents niveaux (officiels) concernant l’autonomie des véhicules:

Aujourd’hui les opérateurs les plus avancés sont au niveau 4. Ils ne sont pas nombreux: Waymo (Google), Apollo Go (Baidu), WeRide, Mercedes Benz (avec WeRide), May Mobility. Seul Waymo est vraiment opérationnel avec un service commercial dans plusieurs villes des Etat-Unis et 250 000 miles parcourus par semaine. Tesla qui vient de lancer son service de robotaxi à Austin n’est encore que niveau 2. L’introduction des LLMs permet un saut du niveau 2 au niveau 3 (exemple de BYD intégrant DeepSeek dans son système de conduite autonome).
Dans tous les cas de figure, il n’y a pas autonomie complète: le chauffeur/superviseur est toujours là, simplement déporté et intervient sur une zone délimitée. Le progrès se mesure au niveau du degré de contrôle humain des véhicules et de l’étendue de la zone de circulation. Plus le système est avancé, moins il y a de superviseurs et plus la zone de conduite est étendue. Waymo est en tête, de loin avec 250 000 miles parcourus par semaine dans quatre grandes villes (Phœnix, San Francisco, Los Angeles et Austin) pour une surface combinée de 494 miles carré (1 300 km carré). Waymo a de plus de nombreux projets en cours dans d’autres villes, aux Etats-Unis et au Japon. On estime qu’en moyenne, un contrôleur déporté contrôle 3 à 5 voitures.
Le mythe du robotaxi Tesla
Pour certains officionados de Tesla, son système FSD (Full Self Driving) va montrer ses capacités dès le mois de juin 2025 à Austin et mettre au rencard tous les autres services, en premier lieu Waymo. Tesla a les données sur des millions de voitures équipées de caméra depuis plusieurs années et un modèle d’imitation des bons chauffeurs opérationnel. Il ne lui reste qu’à obtenir les agréments pour lancer ses voitures en autonomie pleine et entière dans le monde entier. Tesla FSD est l’équivalent de Canvas ChatGPT: plus besoin de chauffeur, plus besoin de code…
La réalité est plus prosaïque. Tesla FSD est niveau 2, encore deux rangs derrière Waymo. Le lancement d’un service de robotaxi à Austin est essentiellement une opération promotionnelle. Il faut regarder sous le capot: combien de voitures par superviseur et sur quelle étendue ? Au départ, le service concerne 10 à 20 voitures, avec un chauffeur sur le siège passager avant et une zone de déplacement réduite aux quartiers les plus sûrs (résidentiels). Un tel déploiement en phase avec le niveau d’autonomie atteint par FSD contraste avec les effets d’annonce: beaucoup de bruit pour rien.
Le combat maintenant va être essentiellement de diminuer le niveau de contrôle, c’est à dire d’augmenter le nombre de voitures par superviseur. C’est là où se situe l’enjeu d’effet d’échelle et non dans le remplacement des LiDAR par des caméras… Comme pour le code, l’automatisation est progressive, soumise au bon vouloir des municipalités et on est probablement encore loin de la pleine autonomie. Il y a de larges marché à prendre qui nécessitent d’écouter la réalité du terrain (en l’occurrence les municipalités) plutôt qu’essayer d’imposer une solution toute faite et généralisée. C’est ainsi que Waymo signe des contrats cadre avec les municipalités pour répondre à leurs contraintes (quartiers à éviter, possibilité d’intervention des agents municipaux pour prendre le volant, etc.)
Cela ne veut pas dire que Tesla n’a pas ses chances dans cette compétition, mais il devra passer par les mêmes contraintes que les autres intervenants et petit à petit augmenter le niveau d’automatisation.
Voici donc deux secteurs majeurs qui vont être redéfinis par l’IA, dont l’automatisation progressive est la règle du jeu. L’introduction des LLMs pour l’un comme pour l’autre est un accélérateur du progrès, sans pour autant permettre une automatisation totale. Le LLM doit s’adapter à la réalité et complexité du secteur. Dans les deux cas, une approche « juste milieu » permet de damer le pion aux nihilistes et de battre les maximalistes au jeu du Lièvre et de la Tortue. Il convient maintenant de se poser la question: cette approche est-elle généralisable à d’autres secteurs de l’économie, offrant de belles opportunités aux entreprises qui mettront l’IA au cœur de leur secteur (non à la périphérie) ?
Généralisation ?
C’est la question à $10 trillions. On voit mal comment un IDE traditionnel pourrait résister à Cursor et comment un service de taxi traditionnel pourrait résister à Waymo ou Tesla. Peut-on imaginer des IA spécialisées dans d’autres secteurs ? C’est à mon avis possible à condition de ne pas avoir une vue trop restreinte de l’IA, cantonnée au LLM de pointe par exemple, mais au contraire adaptée aux réalités du secteur. « In medio stat virtus ».
Exemple de Meta
Meta a également un objectif ultime d’automatiser la vente. Le chemin a été long et tortueux (surtout avec l’opposition d’Apple) mais il est pour le coup presque arrivé à l’objectif, au niveau 5. Cette automatisation a été une construction très progressive et non l’effet d’un modèle magique super-intelligent. Meta s’est d’abord intéressé à l’attribution (savoir quand un clic aboutit à une vente). C’était un gros progrès par rapport au niveau 0 qui consistait à faire un matraquage publicitaire, l’idée étant qu’il en restera toujours quelque chose de positif pour les ventes. Avec l’attribution est venu le ciblage. Meta pouvait définir précisément la clientèle, le message et le timing opportun pour maximiser le taux de clics conduisant à une vente. Enfin Meta grâce au LLMs peut concevoir le message publicitaire et faire une offre de type boîte noire: vous nous donnez le budget, on fait la vente, votre département marketing est remplacé. Voici ce qu’en dit Mark Zuckerberg:
En général, on va arriver à un point où, en tant qu’entreprise, vous venez nous voir, vous nous indiquez votre objectif, vous connectez votre compte bancaire, vous n’avez besoin d’aucune création, d’aucun ciblage démographique, d’aucune mesure, à part être capable de lire les résultats que nous vous fournissons.
Je pense que ça va être énorme, c’est une redéfinition même de la publicité en tant que catégorie. Donc si vous réfléchissez à la part de la publicité dans le PIB aujourd’hui, je m’attends à ce que cette part augmente.
Le parallèle avec Cursor peut être fait: l’automatisation est un processus long et complexe: on ne remplace pas le vendeur par un LLM généraliste type ChatGPT, même amélioré. En même temps l’automatisation change le modèle économique publicitaire de but en banc, son impact économique est considérable.
Les agents
On fait aujourd’hui beaucoup de cas des agents IA, nouvelle avancée majeure après les chatbots. J’ai écrit un article sur le sujet. Au dernier comptage, il y a plus de 15 600 serveurs et clients MCP référencés contre 12 000 quand l’article a été écrit. Les agents sont censés remplacer le travail humain dans de nombreux domaines. C’est en partie vrai: on le voit avec Cursor ou Windsurf: l’agent codeur va pouvoir prendre en charge une partie plus significative du code. L’agent ne constitue cependant qu’une brique de l’automatisation, car il n’intègre pas tout le contexte (en particulier ce qui n’est pas écrit mais bien réel). Le contrôle humain reste nécessaire même si peu à peu il se concentre sur les parties les plus critiques.
L’engouement pour les agents est cependant un signal fort que l’automatisation est en route et va concerner secteur après secteur. Les nihilistes et maximalistes seront battus par les pragmatiques qui chercheront à comprendre au plus près le contexte pour le faire intégrer par l’IA. L’IA est un point d’intégration, non un bonus.
Or, que voit on aujourd’hui ? Mark Andreessen est plutôt sévère:
Le S&P 500 n’est plus vraiment le S&P 500. C’est plutôt le S&P 492 et le S&P 8… Il y a 492 entreprises dans le S&P qui n’ont absolument aucune volonté de foncer vers l’avenir, et 8 qui sont à fond.
Et je dis toujours : “Qui sont ces huit ?” Et tout le monde sait toujours qui sont les huit, parce que c’est complètement évident — ce sont celles qui construisent toutes les nouvelles choses.
Il y a heureusement des acteurs plus modestes et tournés vers le futur qui ne sont pas dans le S&P 500 ! L’alerte est cependant déclenchée. L’écart entre les sociétés intégrées IA et les autres peut devenir un gouffre…
Bonne semaine,
Hervé