


L’IA parle à l’IA
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.

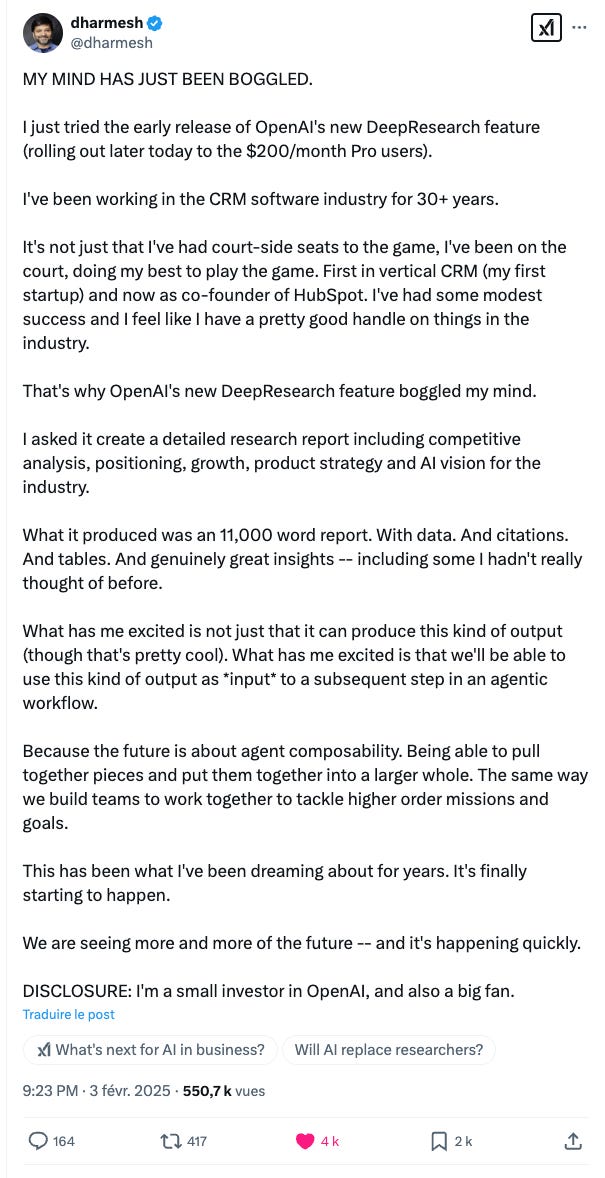
Ce tweet introduit une notion très importante qui est celle de la composabilité de l’IA. Deux IA associées entre elles peuvent désormais se composer pour créer un bond dans l’intelligence:
IA^(n+1)=IA^n x IA^(n-1)
et non:
IA^(n+1)=IA^n x C (où C=constante=intelligence humaine)
L’inflexion de la courbe de l’intelligence artificielle est manifeste à partir de …DeepSeek.
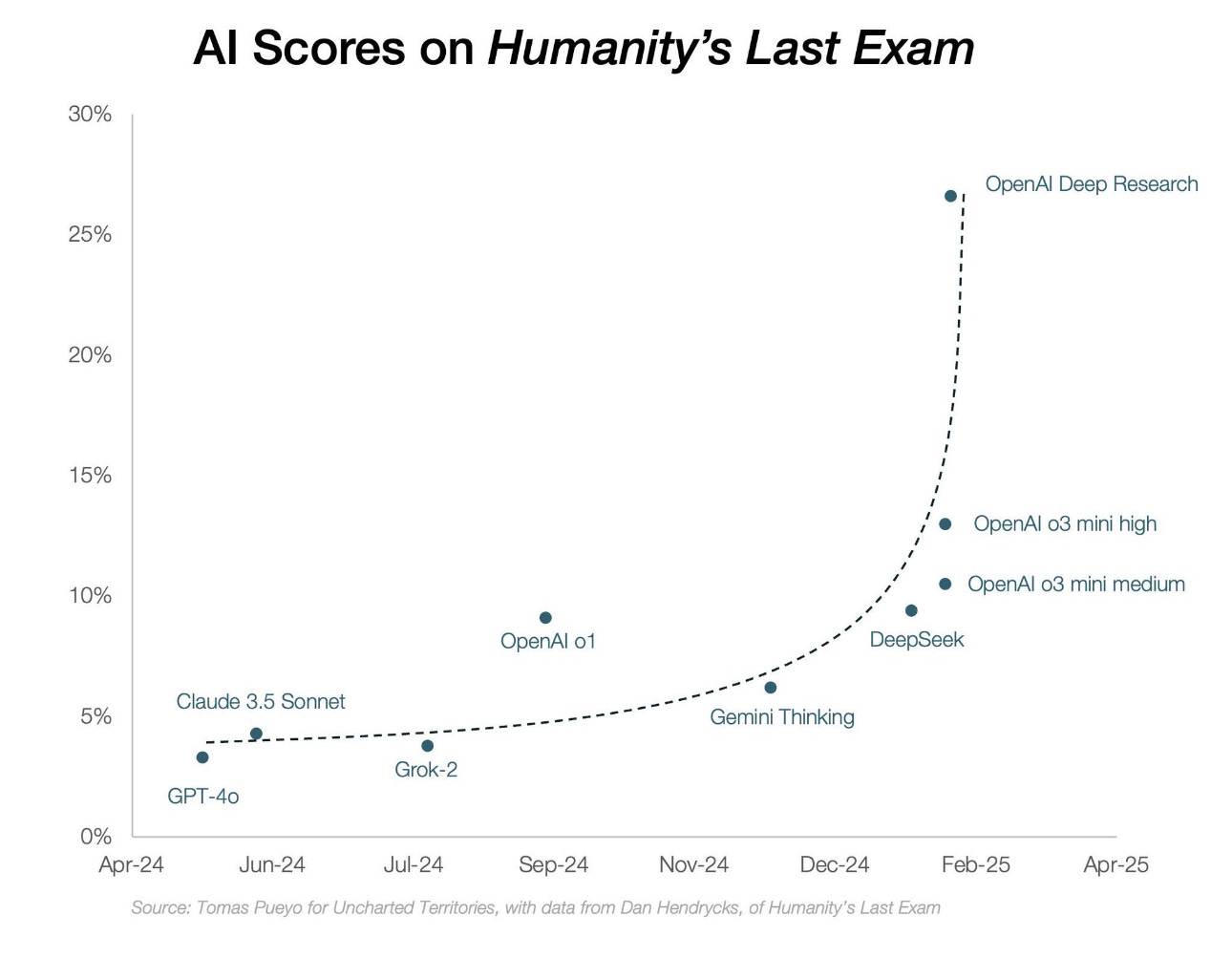
Alors qu’on pouvait jusqu’à présent plutôt s’attendre à cela:
Grâce à la capacité de l’IA de se nourrir d’une autre IA, ses progrès peuvent s’accélérer et par ricochet les tensions entre ceux qui savent l’utiliser et les autres risquent de devenir de plus en plus vives…rapidement !
La révélation DeepSeek
DeepSeek a introduit une innovation déterminante…et open source: l’apprentissage par renforcement sans intervention humaine. Cette technique associée à une autre, celle-ci déjà éprouvée, nommée distillation, a créé la panique sur le marché boursier. Les investisseurs ont soudainement réalisé comme il était facile de copier, voire d’améliorer les modèles les plus sophistiqués. A quoi sert d’investir autant en centres de données pour se faire copier à peu de frais ? Revenons sur ces deux techniques:
La distillation consiste à transférer les connaissances d’un modèle enseignant (comprenant de nombreux paramètres) vers un modèle étudiant plus petit (moins de paramètres) et concis. L’objectif est de reproduire dans le modèle étudiant la manière de prédire des distributions de probabilité ou des sorties similaires à l’enseignant, tout en réduisant la taille du modèle et souvent en accélérant l’inférence. La distillation considère que le modèle enseignant a la bonne réponse et qu’il s’agit juste pour l’étudiant de l’imiter avec moins de ressources. En ce sens, l’étudiant ne peut qu’être moins bon que l’enseignant mais en revanche moins cher à interroger. DeepSeek n’a pas inventé la distillation qui est une pratique courante de tous les promoteurs de modèles de pointes (Meta, Anthropic, OpenAI, Mistral AI, etc). Par exemple, ChatGPT 4o est le modèle enseignant de ChatGPT 4o mini.
L’apprentissage par renforcement pour améliorer un modèle n’est pas non plus une technique nouvelle. OpenAI a utilisé cette technique pour créer ChatGPT Turbo à partir de ChatGPT 4 ou o1 à partir de ChatGPT 4o. La qualité des réponses ou chaînes de raisonnement du modèle initial (en l’occurrence ChatGPT 4o pour o1) est évaluée directement ou indirectement par un référent externe humain dans un but de trouver les meilleures. Contrairement à la distillation, l’apprentissage par renforcement humain améliore le modèle initial en terme de qualité de réponse. Un tel algorithme d’apprentissage est appelé PPO (Proximal Policy Utilization). DeepSeek pour sa part a inventé le concept de GRPO (Group Relative Policy Optimisation), une technique d’apprentissage par renforcement où le référent est interne, consistant en la moyenne des réponses données à un prompt (ou moyenne des chaînes de raisonnement). La réponse du modèle est comparée à la moyenne générée en interne et non à une référence externe (créée par un humain), comme pour le PPO. L’IA (GRPO) améliore le modèle sans intervention humaine, ce qui change l’échelle potentielle d’un tel modèle.
DeepSeek a été très astucieux en combinant les deux techniques. Il a utilisé la première (distillation) pour copier un modèle comme ChatGPT en plus simple. En ajoutant quelques ingrédients novateurs pour économiser en puissance de calcul et mémoire (par exemple l’application d’un MoE de 256 experts), il a créé un modèle performant et pas cher: DeepSeek V3. Puis l’IA GRPO a été appliquée à V3, modèle initial, pour le perfectionner et donner DeepSeek R1 zéro, un modèle de raisonnement fabriqué de manière autonome. DeepSeek R1 zéro est devenu le modèle enseignant qui a alors été distillé pour donner R1, modèle plus concis et efficace que R1 zéro.
En résumé :
-Distillation=compression du modèle
-Distillation associé à GRPO=amélioration du modèle
DeepSeek a ainsi montré que les IA peuvent se composer pour donner une IA en progression géométrique. L’intervention humaine est certes minimale mais il faut nuancer, l’algorithme d’apprentissage par renforcement GRPO est d’autant plus efficace que l’objectif est clair. Les questions de mathématiques, de code ou de logique donneront de meilleurs résultats que des prompts littéraires ou poétiques. Néanmoins, le dé est lancé. Les algorithmes de DeepSeek étant open source, il est désormais possible de s’en saisir pour les améliorer et les adapter à de nouvelles situations, de réduire encore l’intervention humaine par exemple dans les cas moins évidents (droit par exemple). L’IA se compose à une autre IA pour l’améliorer.
Illustration
DeepSeek R1 est capable de générer du code permettant d’accélérer la vitesse d’exécution d’un modèle par deux ou trois. Le développeur Xuan-Son Nguyen a testé l’opération et posté le code sur GitHub. Le code obtenu par un simple prompt sur DeepSeek R1 peut être intégré à un autre modèle pour lui faire utiliser une technique de démultiplication de calcul pour accélérer l’exécution. En l’occurrence DeepSeek R1 a été utilisé pour accélérer la vitesse d’inférence de Llama tout en gardant la même qualité. La conclusion du développeur est édifiante:
En effet, cette demande de modification vise à prouver que les LLMs sont désormais capables d’écrire un bon code bas niveau, au point de pouvoir optimiser leur propre code.
Il y a dans cet exemple intervention humaine (par l’intermédiaire d’un prompt d’abord puis intégration du code dans une bibliothèque qui gère Llama). On peut cependant facilement imaginer qu’un agent IA fasse le travail à la place du codeur. Un modèle pourrait alors automatiquement en améliorer un autre ou s’améliorer lui-même ! Le bon en avant est impressionnant !
Applications en entreprise
Le post en référence en tout début d’article est focalisé non sur la composibilité des LLMs, mais sur la composabilité des agents IA. Parallèlement à l’amélioration exponentielle des modèles que nous venons de voir, on pourrait avoir une amélioration exponentielle du travail des agents IA entre eux dans la même entreprise ou pour le même projet. Les agents seraient alors spécialisés pour éviter les hallucinations et être plus rapides. Là aussi l’impact est considérable. L’IA peut progresser selon deux axes: les LLMs et les agents.
Pour Ronald Coase, économiste britannique, il y a deux moyens pour coordonner l’activité économique: le mécanisme des prix et l’autorité. Les firmes d’après lui existent parce que leurs coûts de coordination interne sont inférieurs aux coûts de transaction externes. Dès lors la coordination se fait à l’intérieur de la firme, sous l’autorité du président directeur général, au lieu de se faire à l’extérieur par l’intermédiaire des prix. Le mécanisme clé de coordination, on l’a vu dans mon dernier article, est la réunion. Microsoft l’a compris en organisant le poste de travail autour de Teams. Le problème est que la réunion est un moyen très imparfait de coordination. Les agents IA, pris individuellement, permettent de faire plus rapidement et de manière consistante le travail que peuvent faire des hommes. Cependant leur apport devient massif à partir du moment où ils se coordonnent ensemble pour réaliser un objectif. Dès lors les coûts de coordination s’effondrent et les firmes qui maîtriseront cette coordination peuvent devenir des géants, le travail à l’intérieur de la firme devenant très bon marché et hyper compétitif par rapport à l’externalisation dans le marché. On peut penser que les sociétés qui maîtriseront les premières la coordination entre agents (les agents travaillant avec les agents) seront les grandes gagnantes de la compétition internationale. Il y aura un point de bascule à partir du moment où la réunion deviendra inutile, c’est à dire que la coordination sera automatisée. Pour le comprendre, songez aux voitures autonomes: la véritable valeur ajoutée se produira quand la majorité du parc sera autonome et que les voitures se coordonneront entre elles: circulation plus fluide, faible taux d’accidents, voitures plus légères et moins cher, moins de CO2, etc.
Si on combine la composibilité des LLMs et celle des agents IA, on peut imaginer l’accélération du progrès de l’intelligence. Cependant cette progression ne se fera pas dans le vide, par l’opération du LLM. Elle entraînera des conséquences au moins à trois niveaux.
Puissance de calcul
Les avancées de DeepSeek R1 interrogent sur la nécessité d’une course en avant sur la construction de centres de données. Si, avec l’apprentissage par renforcement, on peut distiller un modèle de pointe et ensuite améliorer le modèle distillé à peu de frais, quel est la valeur de ce modèle de pointe ? Comment justifier les 100 000 GPUs nécessaires pour entraîner ce modèle de pointe s’il est copié alors qu’il concentre tous les efforts de recherche ?
Pourtant les Big Tech vont investir $330 milliards en centres de données en 2025. Ils ne semblent pas impressionnés par DeepSeek puisqu’ils ont annoncé des augmentations de leurs investissements après la sortie de DeepSeek R1. Sont-ils devenus irrationnels ? Je vois au moins deux raisons à leurs investissements massifs:
La première est que dans une industrie en forte progression, l’intégration triomphe. Généralement, les solutions modulaires percent quand la demande est largement satisfaite et que les connexions peuvent être standardisées, donc statiques. Les concepteurs de modèles de pointe ont tout intérêt à concevoir des produits intégrés à ces modèles qui feront alors la différence car en avance sur les solutions modulaires. C’est ainsi que leurs investissements seront justifiés, pas en vendant le modèle brut. Tesla utilisera ses modèles de pointe dans FSD (module de conduite autonome), Google dans ses nombreuses applications et probablement dans Android, Meta dans ses lunettes de réalité augmentée, Microsoft dans Copilot, etc. Pour que ces produits (intégrés aux modèles) soient efficaces, il est impératif d’avoir une puissance de calcul considérable pour l’inférence. Sinon le risque est le suivant:
Il est donc probable que les investissements continuent car un produit gagnant peut remporter une grande partie du marché, si l’infrastructure est au niveau. C’est la principale loi de l’informatique: « scale, baby, scale ». C’est d’échelle justement que manque cruellement DeepSeek.
La seconde est que le développement de l’intelligence nécessite de la puissance de calcul, que ce soit en entraînement ou en inférence: plus un modèle réfléchit (calcule), plus ses réponses sont pertinentes. Sam Altman, PDG d’OpenAI, dans son blog en a donné une idée:
L'intelligence d'un modèle d'IA est approximativement égale au logarithme des ressources utilisées pour l'entraîner et le faire fonctionner. Ces ressources sont principalement le calcul utilisé pour l'entraînement, les données, et le calcul nécessaire pour l'inférence. Il semble que vous puissiez dépenser des montants arbitraires d'argent pour obtenir des gains continus et prévisibles ; les lois d'échelle qui prédissent cela sont exactes sur de nombreux ordres de grandeur.
Si effectivement l’intelligence d’un modèle IA est une fonction logarithmique des ressources engagées, on peut imaginer le montant astronomique de ressources à déployer pour répondre aux besoins d’une IA en progression géométrique !
Les hommes
L’intelligence n’est-elle qu’une affaire de calcul et L’IA une affaire de puissance de calcul ? A la différence de l’IA, l’homme peut penser en dehors des sentiers battus (out of the box). Ce n’est pas l’IA qui a inventé la chaîne de pensée (Chain of Thought), la division des modèles par expertise (Mixture of Experts) ou l’apprentissage de renforcement sans intervention humaine (GRPO). C’est pourtant ce genre d’innovations qui permet à l’IA de faire des bonds en avant. Aussi. même si dans notre formule mathématique initiale, nous avons postulé que l’intelligence humaine était une constante, elle a ceci de particulier qu’elle peut faire des découvertes, avoir des points de vue innovants. Il est encore à démontrer que le niveau de l’intelligence humaine puisse être atteinte par le calcul. Les hommes restent indispensables pour faire progresser l’IA, mais pas n’importe lesquels. Les codeurs de niveau moyen risquent de voir leurs emplois remplacer par l’IA. Dans la profession du développement informatique, il va rester deux types de profil:
-les ingénieurs d’élite, codeurs à l’occasion, qui feront levier sur l’IA pour mettre en œuvre leurs créations. Ils seront payés des fortunes.
-les testeurs qui ne feront que vérifier que les programmes n’ont pas de bug et fonctionnent comme souhaité (travail de base).
Le milieu, c’est à dire les codeurs traditionnels, étant éliminé. Les sociétés de logiciel chinoises modernes sont particulièrement adaptées à cette évolution, car elles séparent les purs développeurs et les testeurs, contrairement au reste du monde. D’après Jon Y, Asianometry:
Je pense que je dois donner un peu de contexte sur le fonctionnement des principales entreprises technologiques chinoises comme ByteDance et Pinduoduo. La Chine possède de nombreuses entreprises logicielles "classiques", qui ne diffèrent pas structurellement de celles des États-Unis. Je tiens à clarifier ce point. Cependant, les leaders des startups chinoises sont distincts et ont des organisations fascinantes. Leurs équipes de développement sont énormes, parfois composées de dizaines, voire de centaines de personnes. Et seulement environ la moitié de ces membres d'équipe sont des développeurs. L'autre moitié semble être principalement constituée de "personnel opérationnel". Autant que je puisse en juger, c'est un terme générique pour désigner des tâches nécessitant beaucoup de main-d'œuvre. Cela a du sens étant donné le faible coût du travail en Chine. Par exemple, ils s'appuient sur de grandes équipes de contrôle qualité pour tester le code avant sa publication. Ce qui est généralement moins courant aux États-Unis, où il semble que les développeurs soient attendus pour effectuer eux-mêmes les tests de qualité de leur propre code.
La division du travail des développeurs chinois couplé au faible coût de la main d’œuvre est un plus non négligeable pour réussir dans la configuration actuelle. Comment justifier un salaire mirobolant pour tester du code ? Les États-Unis ont le leadership sur l’IA avec de très bons développeurs mais il leur faudra lutter contre une concurrence chinoise bien organisée et moins cher.
Ce type d’organisation “barbell” commence avec le code mais risque de se répandre dans de nombreuses secteurs d’activités.

Les données
Plus l’intelligence artificielle progressera, plus elle sera capable d’exploiter les données publiques même les moins exposées. C’est ainsi que ChatGPT Deep Research est en mesure de produire des rapports complets en exploitant à fond les ressources d’internet (pas seulement les premières pages Google). Avec la prolifération d’intelligence se nourrissant des données publiques, ces dernières n’apporteront plus de valeur spécifique, aussi cachées soient-elles. La transformation de données publiques par l’IA sera banalisée et ne vaudra que son prix de revient. En revanche, la transformation de données privées sera source de valeur ajoutée. Warren Buffett a construit sa réputation sur sa capacité supérieure à analyser de fond en comble les données publiques, rapports annuels et autres, entraînant un grand nombre de suiveurs. La valeur se situait dans les codicilles qui n’intéressaient pas les analystes financiers des grandes banques. Cette époque touche à sa fin. La valeur sera de plus en plus dans les données privées, valeur qui pourra alors être extériorisée par le mécanisme de prix. La progression de l’IA va ainsi pousser à une course sur les données privées:
L’IA renforce ainsi la valeur des entreprises par un double phénomène: 1/ les coûts à l’intérieur de l’entreprise diminuent grâce à l’utilisation des agents IA, 2/ les prix de transaction augmentent, l’exploitation de données privées prenant de la valeur par rapport à celle de données publiques. Évidemment, la condition est une application rigoureuse et systématique de l’IA d’une part et le caractère unique des données privées détenues d’autre part. Une entreprise qui utilise l’IA à l’occasion et dont le savoir faire est banal (commun, dans le domaine public) n’aura aucun avantage particulier.
La valeur du secret
A l’aune de cette emprise croissante de l’IA, Il me parait opportun de méditer sur le livre de Peter Thiel: Zéro to One. L’auteur discerne trois niveaux d’information:
-les conventions
-les secrets
-les mystères
L’information conventionnelle est facile à obtenir mais sans grande valeur ajoutée, les secrets sont difficiles à dévoiler mais apportent de la valeur, enfin les mystères sont impossibles à déchiffrer.

Pour Thiel, on ne crée de la valeur qu’en découvrant des secrets, c’est à dire des vérités sur lesquelles il n’y a pas consensus. Avant d’entreprendre, il faut se poser la question: « Quelle vérité importante très peu de personnes partagent-elles avec vous ? » Une de ces vérités est le passage de zéro à un: Thiel distingue le progrès horizontal (copier ou améliorer ce qui existe déjà , le passage de 1 à n, du progrès vertical (créer quelque chose de véritablement nouveau, passer de 0 à 1). Il soutient que la vraie innovation consiste à inventer des technologies ou des produits jamais vus auparavant, une idée qui choque ceux qui voient le progrès essentiellement comme une amélioration incrémentale.
Peter Thiel pointe avant l’heure, puisque son livre date de 2014, les limites de l’intelligence artificielle. Celle-ci ne produit que du conventionnel (elle cherche le plus probable en moyenne). Malgré tous les progrès de l’intelligence artificielle, il y a de la place pour la créativité…Seulement il ne suffit pas d’être contrariant et de prendre le contrepied de l’intelligence artificielle. Encore faut il trouver la bonne idée !
Apparemment, Liang Wenfeng, fondateur de High-Flyer, un hedge fund à base d’IA, géré à la manière de Renaissance Technologies, a eu la bonne idée. Son fonds patinait sérieusement depuis 2020, la performance n’étant plus à la hauteur de son nom. Il s’est alors probablement souvenu de cette maxime: « Pendant la ruée vers l'or, ce ne sont pas les chercheurs d'or qui se sont le plus enrichis, mais les vendeurs de pelles et de pioches. » C’est ainsi qu’il lance DeepSeek en 2023…
Bonne semaine,
Hervé