


Mistral AI: le petit grain dans la mécanique ?
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
On pensait l’IA générative affaire de gros moyens, de GPUs mis en batteries et de modèles à trillions de paramètres entraînés sur des données massives…Or, Mistral AI, fondé en février 2023, semble rebattre les cartes avec un modèle open source à 7 milliards de paramètres seulement.
De sa propre analyse, son modèle est supérieur à Llama 2 (70 milliards de paramètres) et à GPT 3.5 (175 milliards de paramètres). Et pourtant, Mistral AI n’a pas dépensé grand chose puisqu’il a utilisé les fonds de son premier tour de financement en juin (€105 millions) pour ses deux modèles principaux Mistral-7B et Mixtral-8x7B.
Avec un deuxième tour de financement de €385 millions le 10 décembre, Mistral Ai se donne maintenant pour objectif de concurrencer OpenAI et Google sur ses modèles haut de gamme.
Quels enseignements tirer de cette soudaine percée d’une start up sans moyen dans la cour des grands ?
La banalisation des modèles de fondation
Le nombre
OpenAI a rapidement fait des émules avec son modèle de fondation ChatGPT. Un an après, voici un état sommaire de la concurrence:
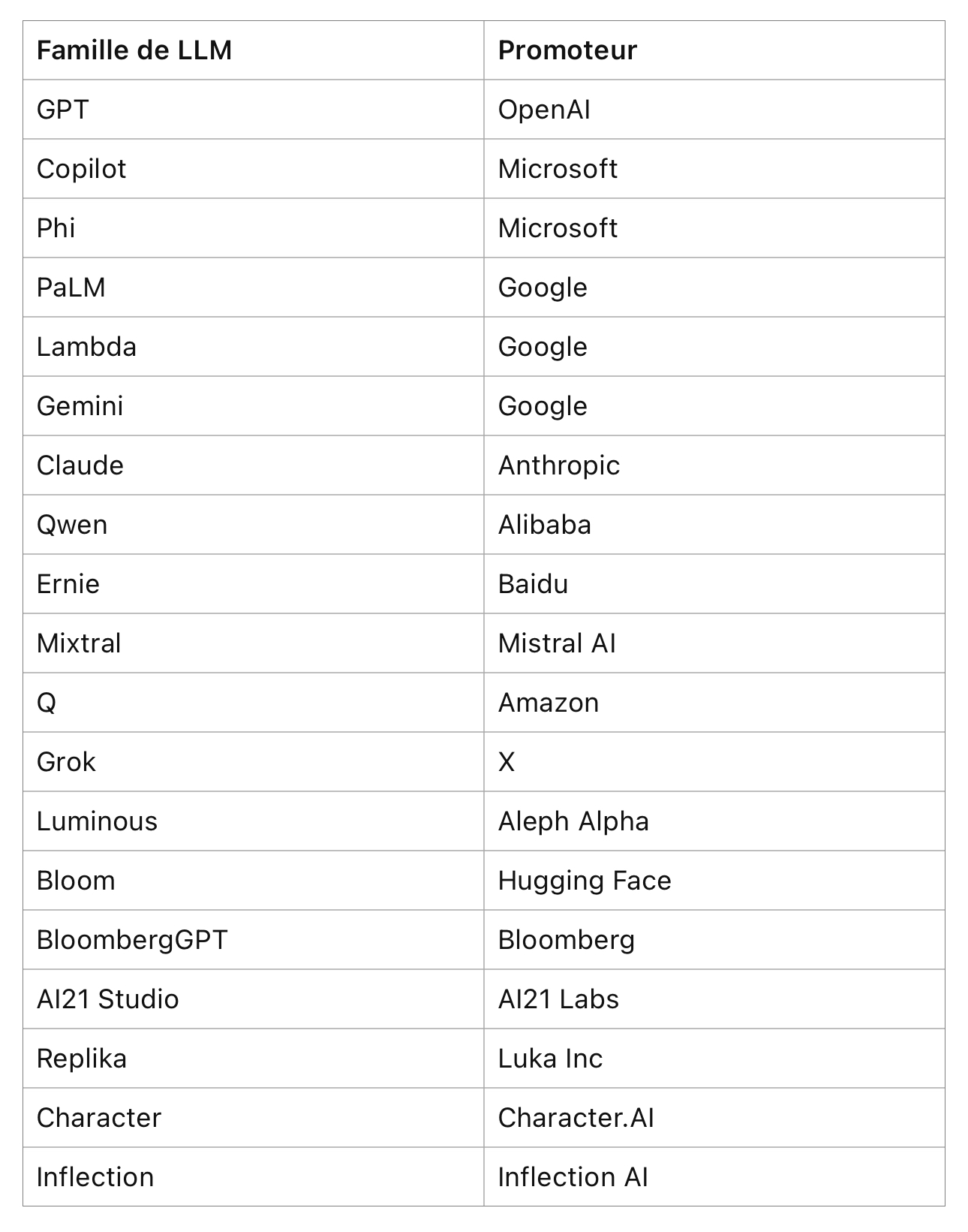
On y voit de grandes entreprises technologiques certes, mais aussi des entreprises plus modestes comme Bloomberg ou des start up comme Mistral AI, Aleph Alpha…Avec l’engouement actuel sur l’IA générative, on peut imaginer le nombre de LLMs dans un an, les fonds de capital développement voulant être de la partie ! Prenons l’exemple d’Inflection AI, une start up américaine qui a créé un LLM digne de GPT-4 selon les benchmarks de place. Entraîner ce dernier a nécessité 5 000 H100 de Nvidia, soit un investissement d’un peu plus de $100 millions. L’équipe Inflection n’est que de 35 personnes. En bref pour faire un bon LLM, il faut:
1/ du talent (généralement des transfuges de DeepMind, OpenAi ou autres grands modèles connaissant certaines recettes du succès)
2/ de la force de frappe GPU pour l’entraînement qu’on peut trouver auprès de clouds GPU. Ainsi Mistral AI a entraîné ses modèles sur CoreWeave .
3/ des données. En l’occurrence les modèles de fondation sont principalement entraînés sur les données du web à l’aide d’instruments open source comme Common Crawl ou C4.
1/ Le talent est rémunéré en fonction du succès. 2/ La force de frappe GPU est subventionnée par les clouds GPUs travaillant à perte pour gagner des parts de marché, clouds eux-mêmes subventionnés par les capitaux privés. Ainsi CoreWeave a levé $2,3 milliards en août pour financer ses opérations (pertes plus probablement) et vaut dans une récente levée de fonds $7 milliards. 3/ Enfin les données peuvent être obtenues gratuitement puis peaufinées par les petites équipes en place pour les rendre plus efficaces. Bref, pour un coût relativement modéré financé par un capital risque gourmand, on peut construire un LLM de qualité GPT 3.5, voire au dessus.
Les LLMs vont probablement pulluler en 2024…
La différenciation
Le LLM est une bête informatique inédite dans la mesure où il hallucine. L’hallucination est le propre du LLM, qui fait office de cerveau droit intuitif quand toute l’informatique jusqu’à présent a été fondée sur la logique du cerveau gauche. Si bien que le LLM est naturellement plus doué à la création qu’à la restitution et analyse des faits. Il peut avoir des intuitions géniales mais sortir aussi des énormités. Dès lors la valeur du LLM est dans le regard de celui qui l’utilise: il peut s’émerveiller des ses réponses hors du commun comme s’énerver de ses inexactitudes.
Devant un tel aléas, les promoteurs de LLMs doivent convaincre de la supériorité de leurs modèles et essayer de la sceller par une marque reconnue. C’est pourquoi, ils se livrent à la guerre du nombre de paramètres (GPT) ou font des démonstrations en chambre des capacités de leur LLM (Google) ou se font noter par des organismes de rating (Mistral) …Au final, la déification d’un LLM est un acte de foi et il est difficile de voir quelle religion va l’emporter…Chaque promoteur devient prosélyte. Les gagnants sont des services comme Poe qui constitue une plateforme de LLM ou Meta qui jette en pâture des LLMs open source pour les banaliser au profit de ses réseaux sociaux.
La chute
La réalité est qu’à moins d’un saut technologique (toujours possible), les modèles de fondation en tant que tel manquent terriblement de différenciation. La conséquence prévisible est:

Le scénario pourrait être le suivant: dans une course à la part de marché, les LLMs cherchent à se se distinguer en pratiquant des tarifs moins élevés que leur voisin. Les financements abondants des sociétés de capital risque rendent probable cette stratégie. Or l’inférence est onéreuse et repose sur une infrastructure dominée par deux intervenants: Nvidia et Google qui n’ont pas d’incitation à baisser leurs prix. ChatGPT le leader et meilleure marque donne le tempo, alors qu’il bénéficie d’un accord spécial avec Microsoft: l’entrée de ce dernier au capital d’OpenAI a été payée non pas en cash mais en crédits GPUs sur Azure pour un équivalent de $10 milliards. OpenAI est subventionné en inférence, alors comment les autres vont ils gagner de l’argent ? D’après Semi Analysis, le 18 décembre 2023:
Le modèle GPT-3.5 Turbo d'OpenAI est beaucoup moins coûteux à exploiter que Mixtral, et OpenAI a des marges assez importantes, principalement grâce à sa capacité à atteindre des tailles de lots très élevées. Cette taille de lot élevée est un luxe que d'autres utilisateurs plus modestes n'ont pas.
OpenAI facture 1,00 $ par million de jetons d'entrée et 2,00 $ par million de jetons de sortie. Mistral, bien qu'ayant un modèle plus coûteux à gérer mais de meilleure qualité, doit proposer un prix inférieur à celui d'OpenAI pour inciter les clients à l'adopter. Ainsi, Mistral facture 0,65 $ par million de jetons d'entrée et 1,96 $ par million de jetons de sortie. Il s'agit en fait d'un preneur de prix, car cette tarification est largement dictée par les forces du marché, contrairement au coût de fonctionnement de l'inférence de Mistral et au rendement cible du capital investi.
Mistral, en plus d’être contraint par ChatGPT l’est aussi par des start up en mal de parts de marché comme Inflection AI qui a levé près de trois fois plus de capitaux que lui ! Si le modèle économique de Mistral n’est pas évident, celui des sociétés qui utilisent son LLM pour facturer leur service ne l’est pas non plus. Voici la grille de tarif de Perplexity AI, moteur de recherche nouveau genre:

Perplexity/Mixtral tarifé à $0,14/$0,56 quand le modèle sous-jacent à est facturé $0,65/$1,96…hum…il y a comme un jeu de chaises musicales en germe financé par le capital risque.

Les bénéfices de l’intégration
Connexion entre cerveau droit et cerveau gauche
Les LLMs à partir d’un certain niveau « intellectuel » sont indifférenciés du fait de leur essence hallucinatoire: ils ont réponse à tout mais leur fiabilité laisse à désirer. Pour se démarquer, ces LLMs vont devoir acquérir l’intelligence rationnelle. Il va leur falloir connecter cerveau droit et cerveau gauche, intelligence intuitive et déductive, modèle probabiliste et déterministe. L’intelligence intuitive est celle des LLMs: elle répond aux instructions par induction, ce qui est une véritable révolution en informatique. En effet, jusqu’à présent les programmes répondaient aux instructions par déduction (si…, alors…) en suivant une approche déterministe.
Première phase: connecter l’existant
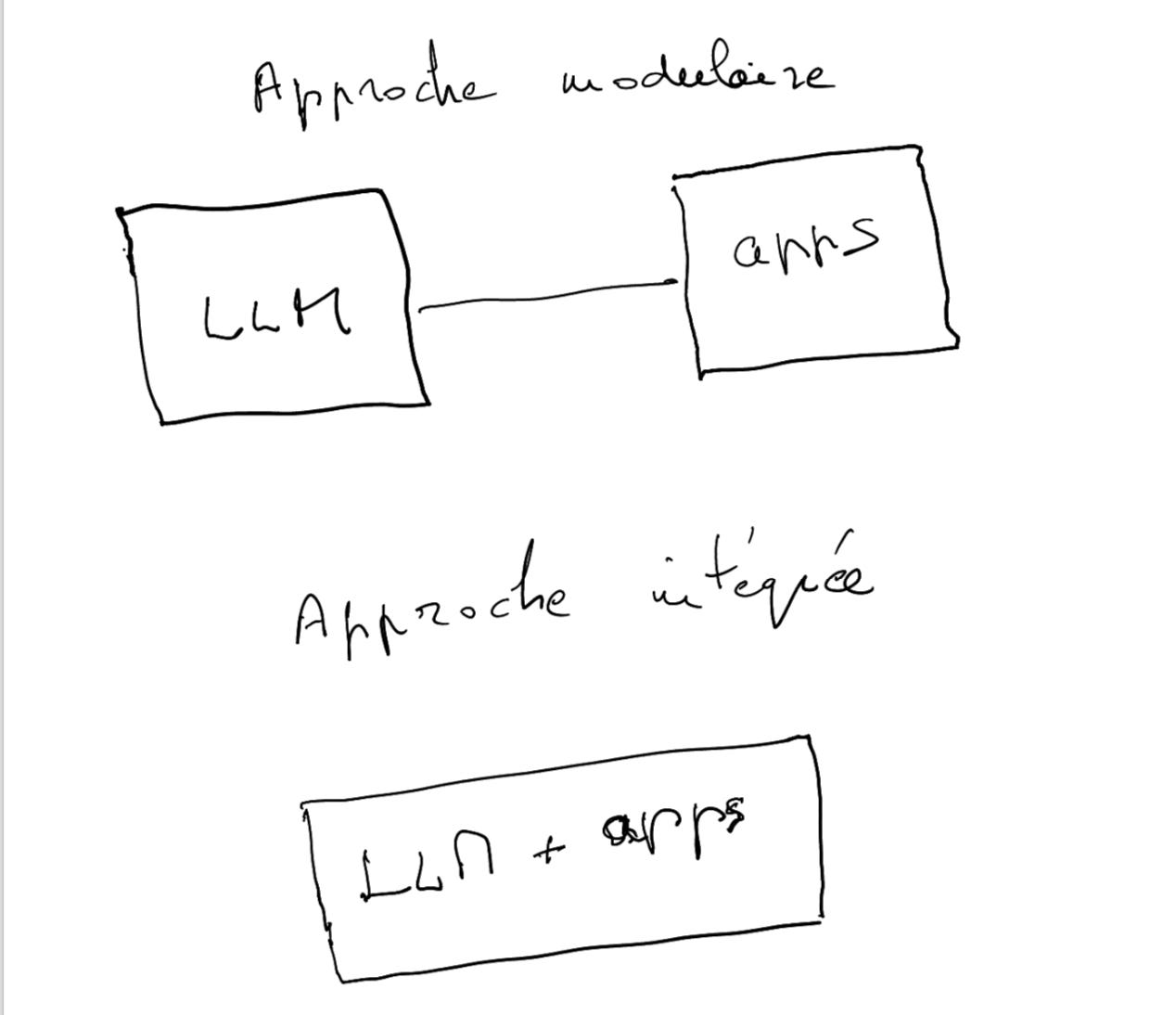
La première phase va consister à connecter les LLMs aux applications logicielles existantes, celles qui fonctionnent par déduction. ChatGPT a fait une première tentative avec la fonction « plug in », disponible pour les abonnés payants. Elle consiste à brancher au maximum trois applications simultanément à ChatGPT. En fonction des questions, ChatGPT va chercher la réponse dans l’une ou l’autre des trois applications. Si par exemple, on connecte ChatGPT et Wolfram Alpha, on va pouvoir résoudre des problèmes mathématiques de haut niveau, sans hallucination possible: le travail est fait non pas par le LLM mais par Wolfram Alpha. Le LLM enverra les instructions et mettra en forme la résolution des problèmes.
Cette approche modulaire qui consiste à connecter deux systèmes différents comme s’il s’agissait de deux pièces de lego laisse à désirer. Car les deux pièces n’ont pas été conçues pour être connectées ensemble. Il y a tout un travail à faire sur l’inter-connexion qui pourra cette fois être source de différenciation. Clayton Christensen dans The innovator’s solution a montré l’importance de commencer par une approche intégrée :
Les clients n'achèteront pas votre produit s'il ne résout pas un problème important pour eux. Mais ce qui constitue une "solution" diffère dans les deux cas de figure suivants: si les produits ne sont pas assez bons ou s'ils sont plus que bons. Nous avons constaté que l'avantage va à l'intégration lorsque les produits ne sont pas assez bons, et à l'externalisation - ou à la spécialisation et à la désintégration lorsque les produits sont plus que suffisants.
Nous sommes clairement aujourd’hui dans le premier cas de figure, celui d’une intégration nécessaire. Cela explique pourquoi l’approche « plug in » est un échec (reléguée en arrière plan de l’abonnement ChatGPT +): la connexion est complexe à établir, les réponses tardent et sont peu satisfaisantes. Le dilemme pour OpenAI est qu’il n’est pas en position de faire de l’intégration. Reprenons les définitions pour le comprendre. D’après le Christensen Institute:
Un produit est modulaire lorsqu'il n'y a pas d'éléments imprévisibles dans la conception de ses pièces. La modularité standardise la manière dont les composants s'assemblent - physiquement, mécaniquement, chimiquement, etc. Les pièces s'emboîtent et fonctionnent ensemble selon des modalités bien comprises et clairement codifiées.
Un produit est interdépendant lorsque la façon dont une pièce est fabriquée et livrée dépend de la façon dont d'autres pièces sont fabriquées et livrées. L'interdépendance entre les pièces exige que la même organisation développe les deux composants si elle espère développer l'un ou l'autre.
Or OpenAI ne contrôle qu’une pièce: le LLM. Pour pallier cet inconvénient, il vient de passer un accord avec le groupe de presse Axel Springer (Politico, Bild, die Welt, Business Insider…) Cet accord lui donne accès au catalogue d’Axel Springer à la fois pour entraîner ses modèles et s’en servir pour donner les réponses aux prompts. Ce n’est pas de l’intégration (il aurait fallu pour cela acquérir Axel Springer) mais un premier pas différenciant par rapport à un LLM lambda.
Dès lors ont un avantage naturel les sociétés qui sont des deux côtés (LLMs et applications) et peuvent développer une intégration:
- Typiquement, les Big Tech qui détiennent à la fois des LLMs et moult applications sont les mieux placées (Microsoft, Google, Meta, etc.). Les données massives qu’ils collectent sur le comportement des utilisateurs leur permettent d’entraîner leurs modèles dessus (pas seulement sur le web comme Mistral) et de prédire leur comportement. C’est idéal pour réussir une intégration.
-Mais aussi des applications spécialisées qui peuvent prolonger leur avantage concurrentiel en intégrant un LLM open source de leur conception (moyen efficace pour éviter la course de la reine rouge)
-Enfin l’acquisition par un LLM d’applications à succès pourrait également être envisagée (aidée par des fonds de capital risque). Puis le LLM pourrait travailler l’intégration.
Le jeu est encore très ouvert mais nécessite une transformation de l’existant.
Deuxième phase: inventer le cerveau gauche
Il s’agit là d’inventer un modèle capable non seulement d’induire (prédiction du prochain token), mais également de déduire. La nature hallucinatoire du LLM serait alors considérablement réduite grâce à un contrôle effectué par l’intelligence rationnelle. Aujourd’hui le LLM n’est qu’un copilote aux intuitions géniales de temps à autre, le pilote humain restant aux commandes et faisant office de cerveau gauche. Demain le pilote sera informatique et intégré au LLM…C’est l’idée du System 2 (IA neuro-symbolique) sur laquelle travaillent plusieurs chercheurs. D’après Wikipedia:
Henry Kautz, Francesca Rossi et Bart Selman ont également plaidé en faveur d'une synthèse. Leurs arguments tentent d'aborder les deux types de pensée, tels que discutés dans le livre de Daniel Kahneman, Thinking Fast and Slow. Ce livre décrit la cognition comme englobant deux composantes : Le système 1 est rapide, réflexif, intuitif et inconscient. Le système 2 est plus lent, progressif et explicite. Le système 1 est utilisé pour la reconnaissance des formes. Le système 2 s'occupe de la planification, de la déduction et de la réflexion. Selon ce point de vue, l'apprentissage en profondeur est le mieux à même de gérer le premier type de cognition, tandis que le raisonnement symbolique est le mieux à même de gérer le second type de cognition. Les deux sont nécessaires pour une IA robuste et fiable, capable d'apprendre, de raisonner et d'interagir avec les humains pour accepter des conseils et répondre à des questions. De tels modèles à double processus avec des références explicites aux deux systèmes contrastés ont été travaillés depuis les années 1990, à la fois en IA et en sciences cognitives, par de nombreux chercheurs[9].
Une IA générative capable de tourner sa langue 7 fois dans sa bouche avant de parler serait susceptible d’inspirer la confiance, de se différencier des modèles de fondation actuels et de remplacer le pilote humain dans des cas spécifiques (où les conséquences d’une erreur ne sont pas trop graves).
L’accès
S’il est un des éléments de la chaîne de valeur qui n’est vraiment pas au point, c’est bien l’accès au LLM. Pour obtenir une réponse d’une IA, il faut prendre son smartphone, ouvrir une app ou web app le plus souvent, se faire reconnaître, taper un prompt pertinent et enfin attendre patiemment la réponse qui finit par arriver quand l’app n’est pas encombrée de demandes. Puis enfin vérifier le contenu de la réponse.
Reprenons notre Christensen: quand un produit n’est pas assez bon pour être standardisé, il faut viser l’intégration. C’est bien le cas de l’accès. Une IA générative n’est pas une app comme une autre que l’on télécharge dans un App Store. L’intégration du LLM avec son mode d’accès (hardware et Os) en offrant un accès direct aux prompts élimine la concurrence. Il devient l’assistant exclusif de l’utilisateur.

On peut d’ores et déjà donner deux exemples qui montrent comment l’accès va être intégré:
Les lunettes Meta Ray Ban
L’IA générative est dans les lunettes, qui voit ce qu’on voit, peut l’interpréter et le restituer dans le creux de l’oreille (micro caché dans les branches). Cette IA est multimodale c’est à dire peut générer de la voix, du texte (ultérieurement des images) à partir d’un prompt vocal ou photo. Elle constitue une rupture dans la mesure où elle élimine les applications. Si par exemple, on veut écouter de la musique, on le demande à l’assistant qui ira la chercher directement chez Spotify. On comprend l’intérêt pour Meta d’un tel dispositif: il supprime le magasin d’applications (qu’il n’a pas) et le remplace par des applications pré-sélectionnées qui se battront pour avoir la place. La condition est naturellement que les lunettes aient plus qu’un succès d’estime. Ce ne sont aujourd’hui que des lunettes de soleil 😎 portées occasionnellement (surtout dans les villes). Or l’intérêt de ces lunettes est également à l'intérieur, pour interpréter un texte web et l’interroger par exemple ou répondre à un mail, etc. Il faut convaincre toute une partie de la population qui ne porte pas de lunettes (notamment les jeunes) et ce ne sera pas évident…
Pixie
The Information, le 14 décembre 2023:
Le déploiement de Pixie, un assistant IA exclusivement pour les appareils Pixel, pourrait stimuler l'activité matérielle de Google à un moment où les entreprises technologiques se précipitent pour intégrer de nouvelles capacités d'IA à leur matériel. Pixie utilisera les informations sur le téléphone du client - y compris les données issues de produits Google comme Maps et Gmail - pour évoluer en une version beaucoup plus personnalisée de l'Assistant Google, selon une des personnes ayant connaissance du projet. La fonctionnalité pourrait être lancée dès l'année prochaine avec le Pixel 9 et le 9 Pro, a déclaré cette personne."
Google est tiraillé entre deux modèles économiques: l’intégré (Search, maps, YouTube…) et le modulaire ((Android, cloud). Le modèle naturel de Google reste l’intégration pour offrir le produit parfait (search +infrastructure géante par exemple). En cela Google ressemble à Apple. C’est souvent en réaction et en retard que Google choisit une approche modulaire: Android était une alternative à l’IPhone, Google Cloud une riposte à AWS et Azure.
Il se trouve cette fois que Google est en avance sur Apple. La société a conçu le modèle Gemini nano qui fonctionne en local (latence très faible, réponses immédiates) qui n’est pas comparable à Siri. Il équipe d’ores et déjà le Pixel 8 pro et peut effectuer certaines fonctions comme le résumé d’une conversation ou la réponse aux messages WhatsApp. L’avantage de Gemini nano par rapport aux LLMs existant est la rapidité des échanges. Ce n’est qu’un premier pas vers Pixie qui nécessitera une reconfiguration du hardware et de l’OS: l’objectif est de construire le smartphone en fonction de l’assistant et non l’inverse.
Google a une occasion unique de renverser la table:
la part de marché du Pixel Phone est ridicule par rapport à celle de l’iPhone
Le chiffre d’affaires du Google Play Store est environ la moitié de celui de l’App Store.
Google n’a rien à perdre à lancer un smartphone deuxième génération qui reléguerait au second plan les apps au profit de l’assistant Pixie. Ce dernier pourrait être intégré avec les nombreuses apps de l’univers Google, bénéficier de son infrastructure et données massives. Cela mettrait Apple en position délicate: lui faudrait-il suivre Google ou protéger son App Store avant tout ? Si le projet Pixie réussit, Google pourrait choisir une monétisation par le hardware au lieu de publicitaire, pour ce qui concernerait son produit phare, le Pixel. Le reste des appareils Android devrait se contenter de Gemini Ultra intégré aux apps Google.
Avec une innovation de rupture comme celle des LLMs, il semble bien qu’on soit entré dans une époque d’intégration. Rappelons Christensen: la phase d’intégration précède la phase modulaire. L’avenir est au LLM intégré (à un hardware, OS, app, autre type d’IA…)
Or, le marché du LLM est parti tambour battant sur une approche modulaire, encouragé par les fonds de capital risque. Seize ans après la révolution de l’iPhone, produit intégré par excellence, l’approche modulaire s’est logiquement imposée (Android, magasins d’applications, cloud…). On a fini par oublier que le LLM n’était pas suffisant en tant que tel malgré ses prouesses et qu’il fallait maintenant penser intégration. Les Big Tech en sont conscientes mais le reste du marché et les sociétés de capital risque ?
On comprend la fierté française autour de Mistral AI. Mais le LLM n’est qu’une petite étape sur un long chemin…
Bon bout d’an,
Hervé