


Part 1: IA, bulle ou super-cycle ?
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
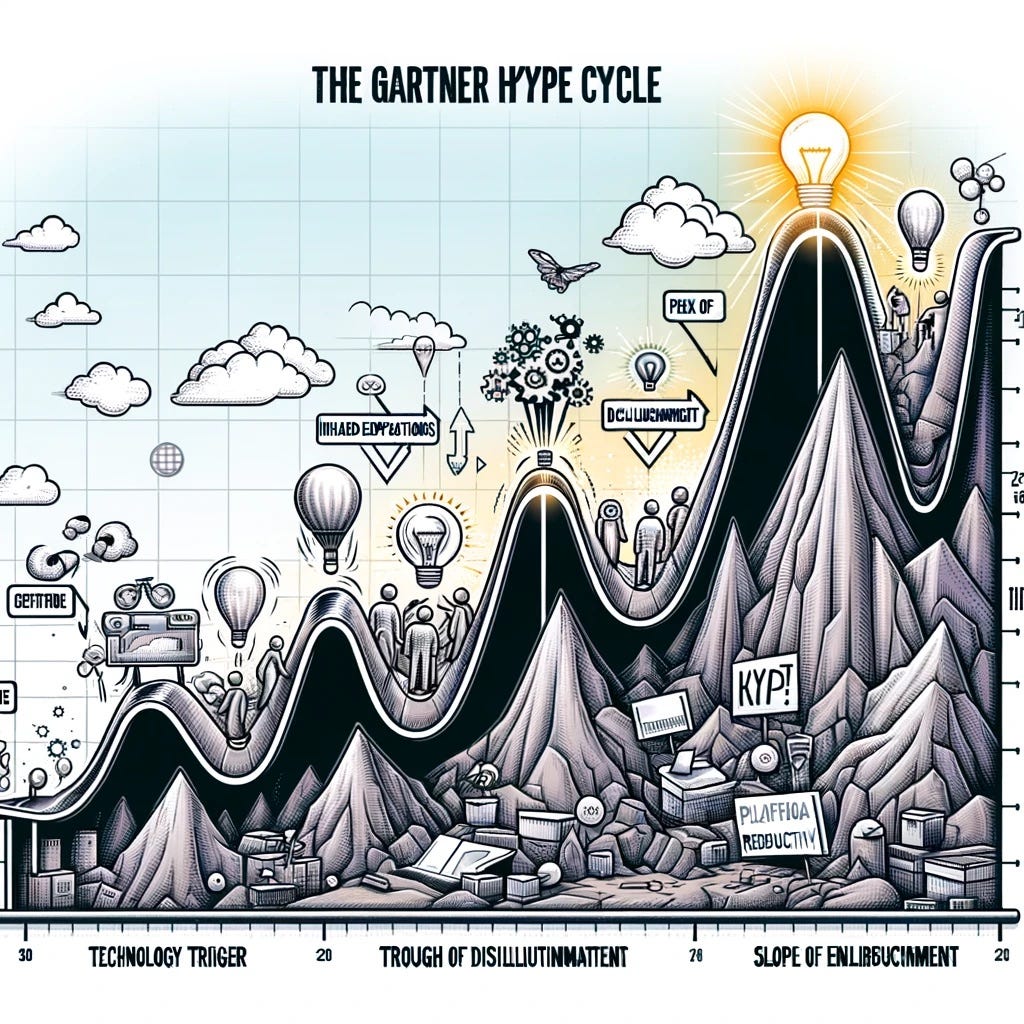
D’après Perplexity:
Le cycle de hype de Gartner décrit l'évolution typique d'une nouvelle technologie à travers 5 phases:
Lancement (Technology Trigger) : La technologie émerge et suscite beaucoup d'intérêt initial.
Pic des attentes exagérées (Peak of Inflated Expectations) : L'enthousiasme et les attentes atteignent un sommet, souvent au-delà des capacités réelles de la technologie à ce stade.
Creux de désillusion (Trough of Disillusionment) : La technologie ne répond pas aux attentes élevées, entraînant une déception et une perte d'intérêt.
Pente de l'illumination (Slope of Enlightenment) : Une meilleure compréhension des capacités et limites réelles de la technologie émerge. Certaines entreprises continuent les expérimentations.
Plateau de productivité (Plateau of Productivity) : La technologie atteint sa maturité et son adoption à grande échelle avec des avantages clairs et pratiques.
C’est ainsi que le cycle de l’internet s’est développé: l’enthousiasme initial a provoqué une construction massive d’infrastructure de télécommunications longue distance et une bataille pour acquérir les serveurs derniers cris. Cependant, même si le chiffre d’affaires de l’internet était loin d’être négligeable en 2000 ( $8 milliards pour la publicité en ligne et $40 milliards pour le commerce en ligne), les usages ne nécessitaient pas un tel déploiement de moyens. Il n’y avait pas d’application pour exploiter cette infrastructure moderne, même si on les pressentait. YouTube et Netflix n’étaient pas nés; Amazon pouvait se contenter d’une bande passante médiocre pourvu que la livraison fut rapide; les blogs écrits avaient surtout besoin d’être mis en avant dans le résultat des recherches. La déconnexion entre les besoins du moment et les investissements réalisés a créé alors cette grande désillusion. La progression des produits ne nécessitant pas de bande passante extraordinaire (texte et commerce), elle n’était pas un paramètre fondamental. Les cash-flows ont manqué pour supporter le poids de la dette et la capitalisation astronomique des sociétés internet. Il a fallu près de dix ans pour accéder à la pente de l’illumination. Cette expérience douloureuse a marqué les esprits durablement, comme tous les krachs.
Où en sommes nous aujourd’hui ? Des infrastructures massives de calcul parallèle sont mises en place en prévision d’une demande future, comme en témoigne la progression du chiffre d’affaires de Nvidia (l’exercice 2024 se termine en janvier 2024):
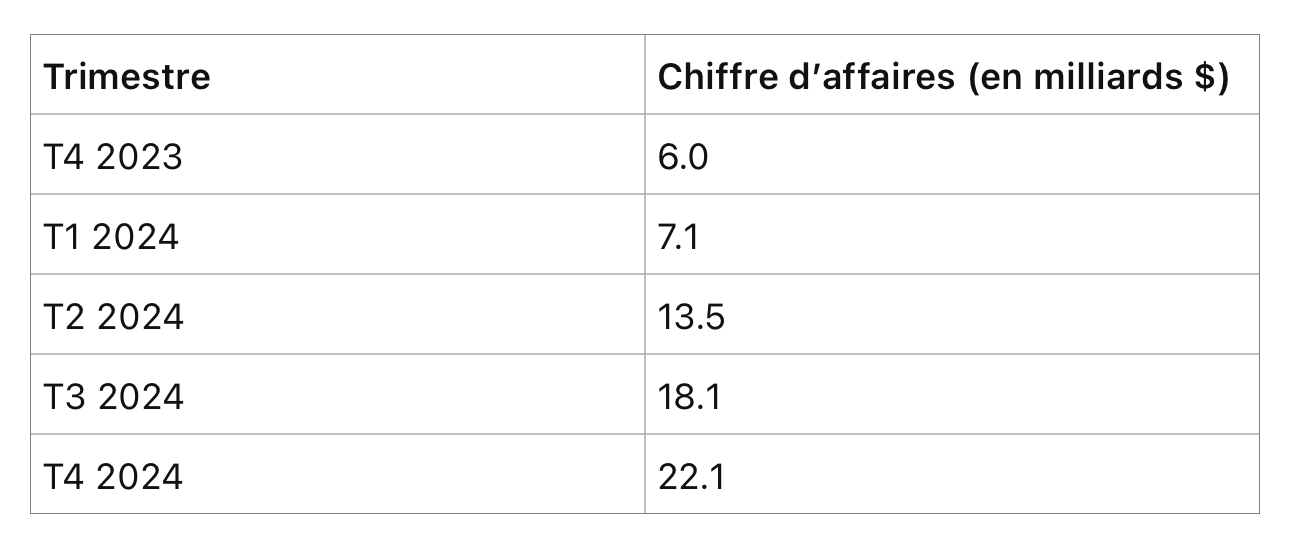
Où sont les produits commercialisables à part ChatGPT qui aux dernières nouvelles (décembre 2023) réalisait un chiffre d’affaires annuel récurrent de $1,6 milliard ? N’y a t’il pas une déconnexion entre investissements et produits qui pourrait se traduire en vallée de désillusions?
Le contexte
Il ne peut être plus différent de la fin des années 1990. Le marché revient d’un krach technologique lié à la hausse des taux (2022). Si l’on exclut quelques cas d’espèce comme Nvidia, il n’y a pas de bond dans les dépenses en infrastructure technologiques et celles-ci sont financées par les cash-flows (à la différence des années de taux zéro). L’évolution du chiffre d’affaires de TSMC, le fondeur par excellence des puces Nvidia mais aussi de toutes les puces haut de gamme hormis celles d’Intel, ne montre pas d’augmentation massive:
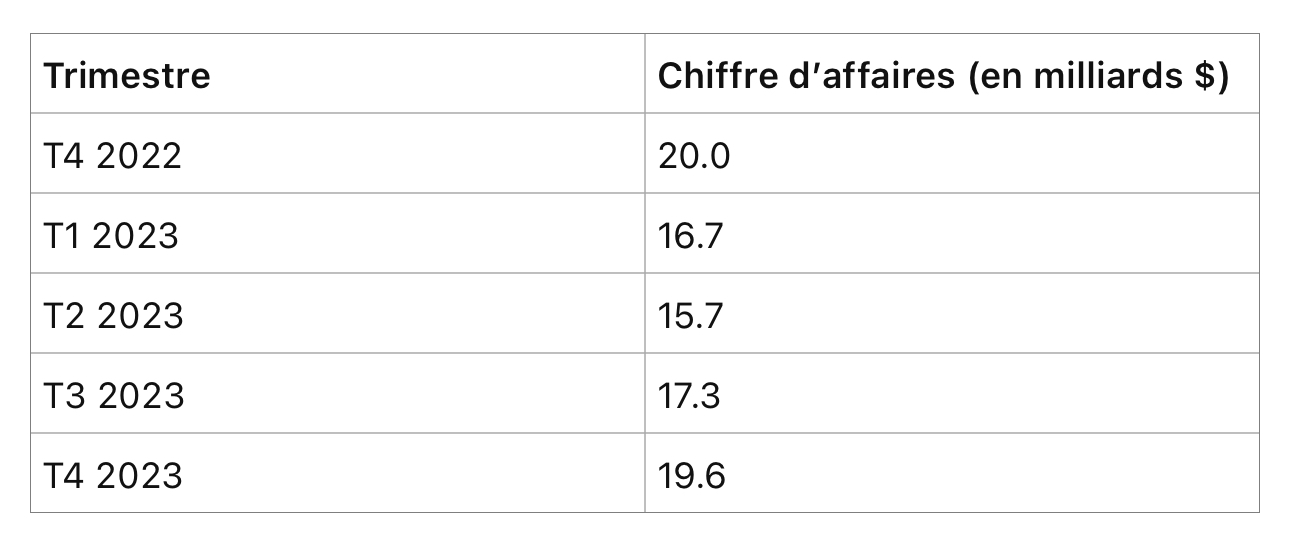
Certes 2024 s’annonce meilleur pour TSMC, mais pas au dessus de la moyenne des années 2020 à 2022. Il en va de même des dépenses d’investissement des Big Tech:
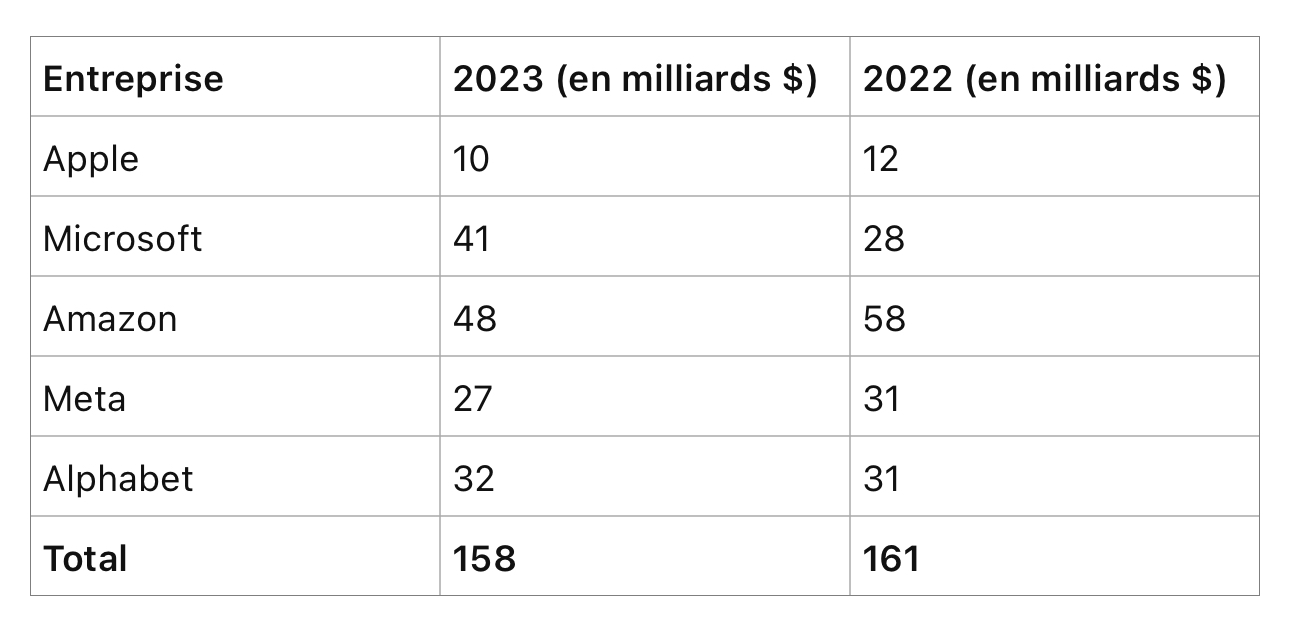
Même en rajoutant les investissements dans le capital des grands promoteurs de modèles comme Open AI ou Anthropic par exemple ($30 milliards environ dont une bonne partie par les Big Tech), on ne constate pas une envolée des investissements.
Il y a plutôt un transfert de dépenses d’une catégorie (serveurs et centres de données CPU) à une autre (serveurs et centres de données GPU), dans le cadre d’une saine gestion, comme le montrent les cash-flows opérationnels de ces mêmes Big Tech confortables et en amélioration:
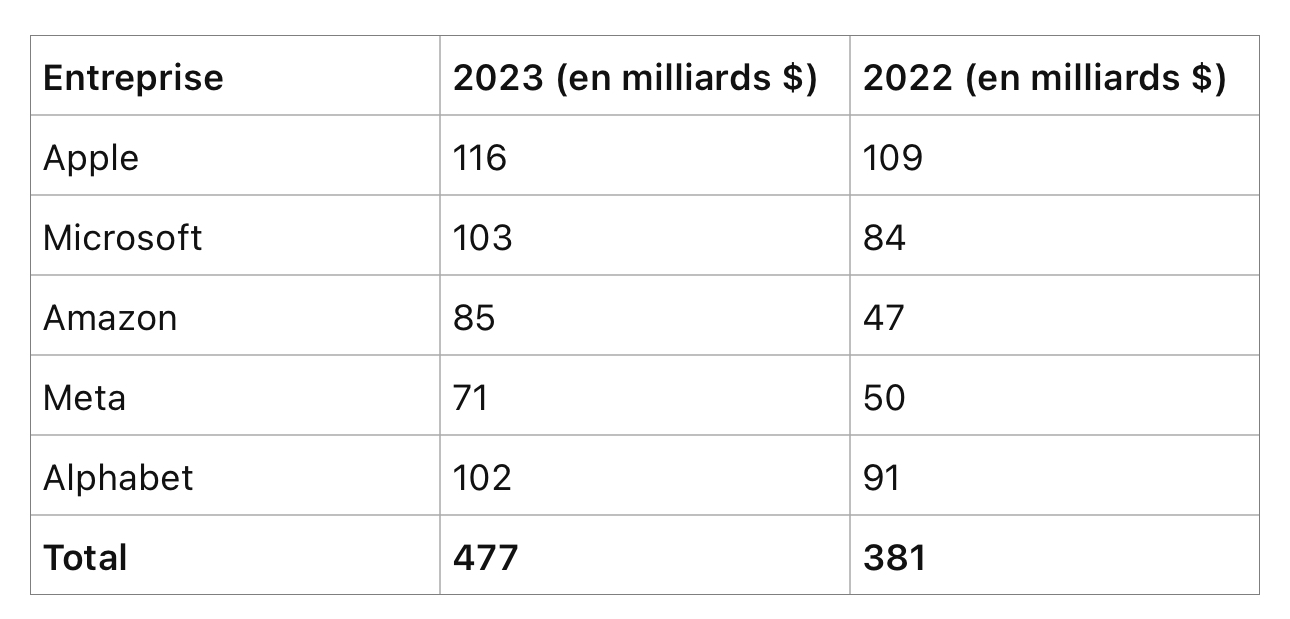
Sachant que la majeure partie des investissements en IA générative proviennent de ces Big Tech, il n’y a pas désillusion dans la demeure. Mais il faut aller plus loin pour comprendre le super-cycle se déroulant sous nos yeux.
Un produit de consommation
L’Iphone
Le cycle de hype de Gartner n’est qu’une théorie. Un cycle récent lui a échappé: celui de l’iPhone datant de 2008; ce dernier est intéressant à analyser pour notre sujet. L’iPhone a transformé un produit de bureau (le PC) en produit de consommation (smartphone). Il y avait à l’époque une certaine incompréhension face à ce produit innovant: il était très cher par rapport à un Nokia par exemple qui semblait faire l’affaire pour la majorité des usages (message et appels téléphoniques). Il était considéré comme un gadget de consommation par rapport au sérieux Blackberry qui semblait l’instrument idéal pour la communication d’entreprise. Or l’iPhone ne se battait pas sur le marché du téléphone mais sur celui de l’ordinateur (en concevant un produit pour les développeurs). Il en a résulté un super-cycle technologique sans véritable retour:
1/ le marché de l’informatique s’élargissait considérablement: potentiel d’1,5 milliard de smartphones par an au lieu de 300 millions de PC.
2/ Étant un produit de consommation, l’iPhone n’était jamais assez bon, ce qui poussait à une intégration continue de l’ensemble des parties le constituant (système d’exploitation et hardware) pour le rendre plus performant, plus fluide, plus facile à utiliser. Le reste de l’écosystème se divisait en parties modulaires pour le servir (cloud).
3/ Grâce à ce marché sûr, stable et croissant, l’écosystème B2B ( infrastructure, plate-formes, applications cloud) a pu se développer d’abord pour l’iPhone puis dans de multiples directions pour servir le consommateur puis l’entreprise (YouTube, Maps, Zoom, Slack, Twilio, Instagram, etc. sur infrastructure AWS d’abord puis Azure et Google Cloud). L’infrastructure d’entreprise s’est calée sur l’infrastructure de consommation. Cela a pris du temps: il a fallu 10 ans pour que les applications d’entreprise (SAAS) réalisent un chiffre d’affaires de $3 milliards. Le marché du consommateur donnait un effet d’échelle aux acteurs leur permettant d’ajouter un nouveau marché, celui de l’entreprise. Pour boucler la boucle, l’iPhone a fini par être l’ordinateur dominant dans les entreprises ! Qu’est devenu le Blackberry ?
L’IA générative
L’IA générative est à l’IA traditionnelle, ce qu’est l’iPhone au PC. C’est le point le plus important à retenir pour comprendre le super-cycle en formation. Jusqu’en 2022, l’IA était invisible utilisée par certaines entreprises pour de la prévision (fraude, recommandation, recherche…). Il s’agissait principalement de trouver les cohortes aux mêmes comportements dans le cadre d’une segmentation de marché. (PayPal, Netflix, Facebook, etc). Seules quelques entreprises, généralement des tech, étaient concernées. Les serveurs traditionnels fortement pondérés en CPUs étaient suffisants et peu onéreux pour la plupart des usages, d’autant que le partage des données et autres techniques déterministes (règles) réduisaient le calcul de probabilité.
Arrivent coup sur coup sur le marché, à l’été 2022, Midjourney (génération d’image) puis ChatGPT (génération de mots). Ces deux produits d’IA s’adressent directement au consommateur, une première dans l’histoire de l’IA. L’effet « whaou » est là comme pour l’iPhone. Les consommateurs consomment individuellement des GPUs logés chez les opérateurs cloud, une première. Le marché potentiel soudain s’élargit à 8 milliards d’individus au lieu de ne concerner directement que quelques entreprises technologiques. Après un an et quelques mois, le nombre d’utilisateurs mensuels de ChatGPT est estimé à 180 millions. Cette trajectoire est digne de celle de l’iPhone. Il faut ajouter Midjourney, Claude, Gemini et les autres pour avoir une idée du phénomène.
Le produit plaît au consommateur, les chiffres l’attestent, mais il est trop difficilement accessible, trop lent, pas assez fiable et trop limité dans ses possibilités. Il a une grande marge d’amélioration, c’est pourquoi les parties les plus proches du consommateur seront l’objet de tentatives d’intégration: le hardware et le produit d’IA, comme pour l’iPhone le hardware et iOS (cf le projet de hardware de Dan Yves et Sam Altman par exemple ou les Meta Ray Ban).
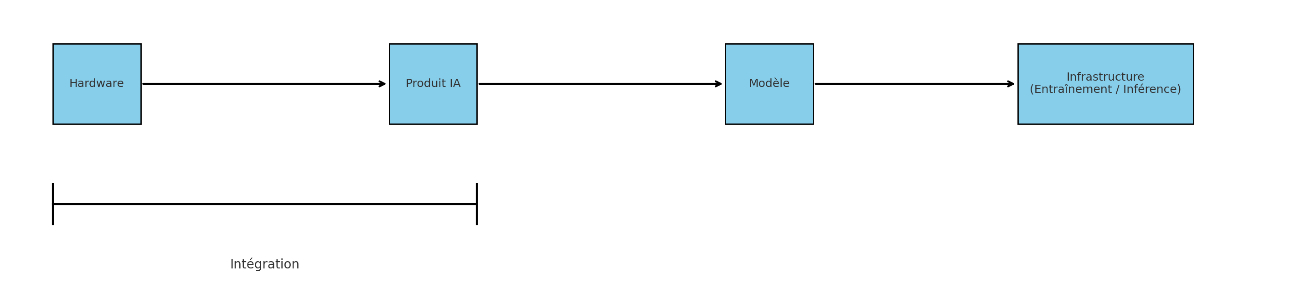
Certains acteurs comme Google ou OpenAI peu à l’aise avec le hardware essaieront plutôt l’intégration produit/modèle. C’est également le cas de Perplexity AI par exemple. Il faut noter cependant que plus on s’éloigne du consommateur, moins on maitrise la distribution et plus l’intégration devient instable.
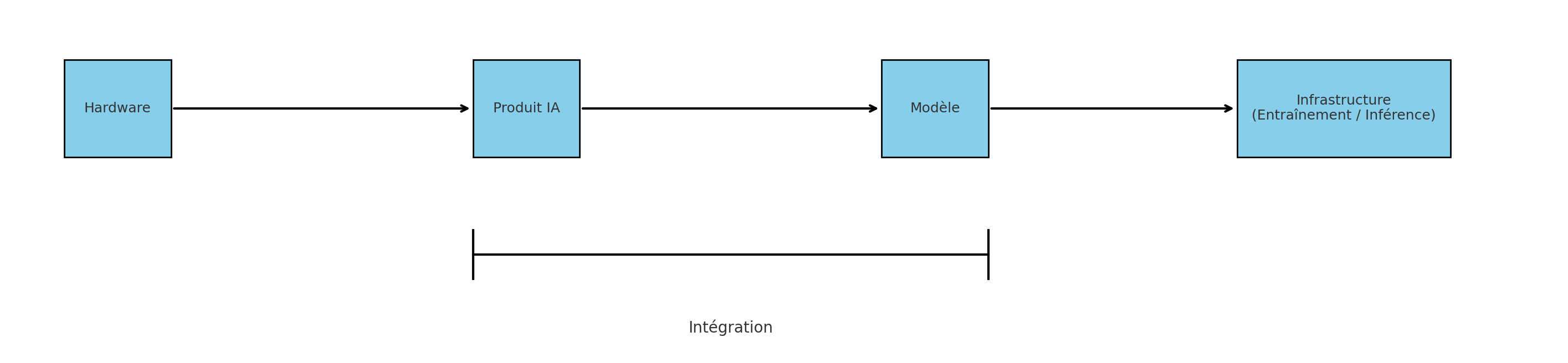
Les parties modulaires (non intégrées) devront elles se battre sur l’effet d’échelle avec un modèle économique horizontal.
L’intégration, à la manière de l’iPhone fait rêver beaucoup d’acteurs. L’histoire montre que même avec une croissance limitée, l’intégration permet de garder la position la plus prisée dans une chaine de valeur. C’est l’exemple d’Apple qui capitalise $ 2,7 T avec une croissance annuelle du chiffre d’affaires de seulement 8 % sur les cinq et dix dernières années.
Christensen revisité
Clayton Christensen a conçu deux théories fondamentales pour comprendre l’évolution de la technologie:
La première est la loi de conservation des profits attractifs: dans une chaîne de valeurs donnée, il existe une juxtaposition nécessaire de processus modulaires et intégrés, de banalisation et de dé-banalisation, afin d’optimiser les performances de ce qui n’est pas encore assez bon. Quand la modularité et la banalisation font disparaître les profits attractifs à un stade, l’opportunité de gagner des profits attractifs avec des produits propriétaires émerge généralement à un stade adjacent. Les profits se font là où il y a intégration, intégration nécessaire pur répondre à une demande toujours plus exigeante. L’inter-opérabilité contraint l’expérience client dans la mesure où elle impose un standard aux différents modules, qui ne concourent plus ensemble à satisfaire les exigences dudit client.
La théorie de la disruption: la disruption est un processus par lequel un produit ou service prend initialement racine dans des applications simples en bas d’un marché, puis monte inexorablement en gamme, finissant par déplacer les concurrents établis.
L’implication de ces deux théories est qu’une société proposant un produit intégré, qui génère une bonne partie des profits d’une chaîne de valeur, va être poursuivi par des concurrents bas de gamme qui se contentent d’assembler des parties modulaires. Dès que le produit sera suffisamment bon, l’approche intégrée ne servira plus à grand chose et sera défaite par l’approche modulaire. Le profit se déplacera ailleurs. C’est ainsi par exemple qu’Intel (conception et fonderie intégrées) s’est fait rattraper par AMD (conception) et TSMC (fonderie): chacun est devenu meilleur dans son domaine propre alors que l’intégration n’apportait plus grand chose (dans les premiers temps, elle permettait d’anticiper le rythme effréné de progression de la loi de Moore). De même le Macintosh d’Apple n’a pas résisté à Compaq (PC) et Microsoft (OS). Les exemples abondent…
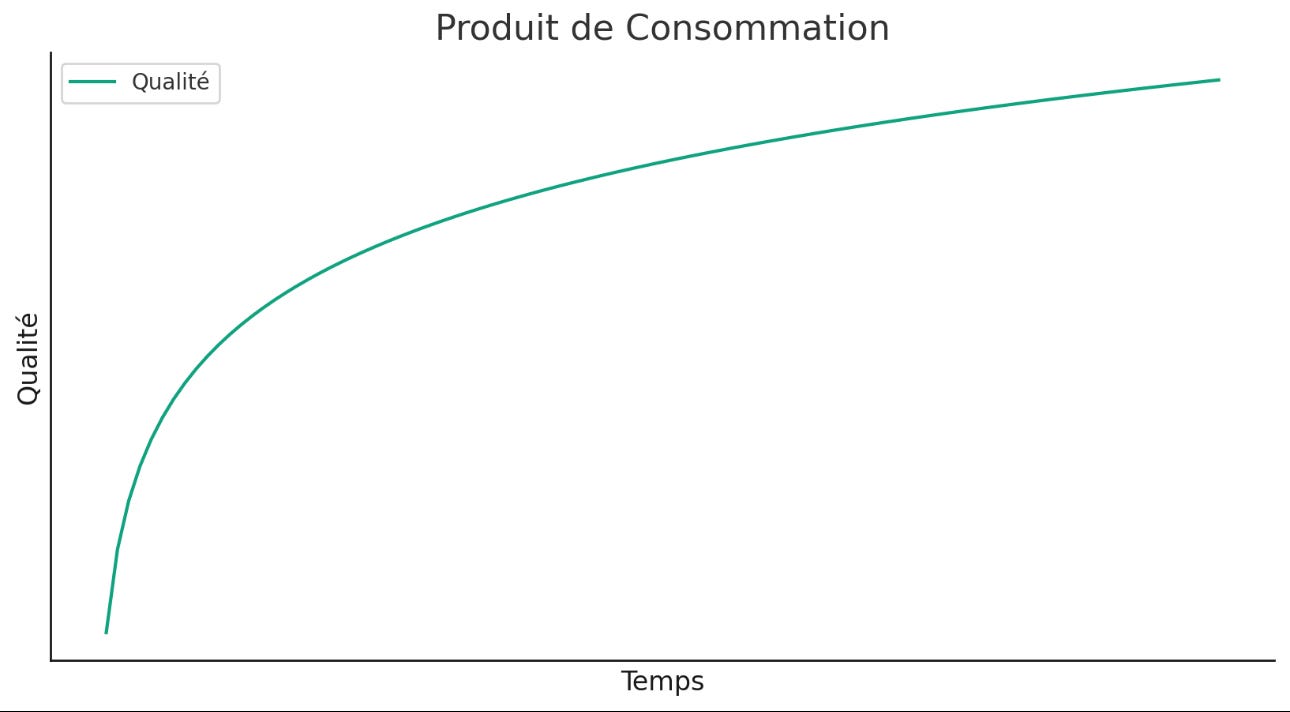
Christensen a toujours pensé qu’Android finirait par triompher de l’iPhone. Il s’est trompé sans que cela ne remette en cause ses théories. En effet, l’iPhone n’a jamais été assez bon dans l’œil du consommateur et il ne l’est pas encore à la génération 15. Les conditions de la disruption ne sont pas réunies. Il y a en fait une grande différence entre les produits de consommation et les produits d’entreprise: les premiers ne sont jamais assez bon (effet wahoo nécessaire); les seconds sont satisfaisants quand ils font le job. La dynamique de progrès n’est pas la même.
-produits de consommation:
-produits d’entreprise:
Quand un produit de consommation définit le marché l’exigence de perfection implique que l’approche intégrée triomphe durablement, les profits l’accompagnant; quand c’est l’entreprise, la disruption et l’approche modulaire sont au coin de la rue. Seul compte l’effet d’échelle.
IA générative: consommateur ou entreprise ?
De plus en plus, le marché du consommateur précède celui de l’entreprise. On l’a vu avec l’iPhone, on le constate de plus en plus depuis le Covid et le télétravail qui estompe les frontières entre les deux mondes: Airbnb sert le consommateur et le travailleur désormais. Force est de constater que l’IA générative a démarré en trombe comme produit de consommation, que ce soit avec ChatGPT, Claude ou Midjourney. Leur chiffre d’affaires annuel combiné doit être voisin de $2,5 milliards aujourd’hui (estimation personnelle), montrant qu’il y a un réel marché de consommation pour les produits d’IA générative. On peut y rajouter FSD v12 de Tesla qui adopte la technologie pour son autopilot.
Côté entreprise, malgré tous les discours, les produits sont rares. Github Copilot, le produit parfait pour une IA générative, ne compte qu’un million trois cent mille souscripteurs dans 53 000 organisations (2024), soit un chiffre d’affaires annuel de $600 millions. Cohere, compétiteur sérieux d’OpenAI se spécialise sur les entreprises. D’après The Information:
Cohere a tenté de se différencier de ses plus grands concurrents en vendant sa technologie uniquement aux entreprises et en évitant la course aux chatbots pour consommateurs déclenchée par ChatGPT. Et ces derniers mois, les dirigeants de Cohere ont décidé de ne pas concurrencer OpenAI et d'autres dans le développement des modèles d'IA les plus grands et les plus avancés, souvent connus sous le nom de modèles de pointe, a déclaré une personne ayant une connaissance directe de la décision. Au lieu de cela, la start-up se concentre sur la technologie connue sous le nom de génération augmentée par récupération, qui vise à réduire la tendance de l'IA à halluciner ou à donner des réponses incorrectes, a indiqué cette personne.
Le chiffre d’affaires récurrent annuel de Cohere s’élevait à $130 millions en décembre 2023. Il espère $300 millions en 2024 quand OpenAI en attend $5 milliards. Les RAGs dont on attend beaucoup pour éviter les hallucinations ont du mal à percer: chez ChatGPT, le magasin de GPTs représente 1,3% des requêtes seulement ! C’est symptomatique du manque d’échelle de l’IA d’entreprise par rapport à l’IA de consommation.
Même Microsoft qui domine le marché de l’entreprise ne veut pas laisser aux autres le produit de consommation: après l’essai infructueux de BingChat, il acquiert de manière déguisée Inflection, créateur du bot Pi, une IA émotionnelle. Il s’adjoint ainsi les services de Mustafa Suleyman, une référence dans le domaine de l’IA.
Le contexte est parfait pour que l’IA générative se développe d’abord comme un produit de consommation et qu’elle définisse ainsi le marché futur destiné aux entreprises.
Produits de consommation
Les Big Tech ont le cash et la distribution: elles vont investir pour fabriquer des modèles multi-modaux allant jusqu’à l’intelligence générale. Elles se positionnent: Google avec Gemini, Meta avec Llama, Microsoft avec OpenAI et Amazon avec Anthropic. Les produits devront être toujours plus accessibles, toujours plus rapides, toujours plus étendus dans leur capacité, avoir toujours plus de mémoire. Écoutons Mark Zuckerberg (février 2024):
« À l'avenir, l'un de nos principaux objectifs sera de créer les produits et services d'IA les plus populaires et les plus avancés. Si nous réussissons, tous les utilisateurs de nos services disposeront d'un assistant IA de classe mondiale pour les aider à accomplir leurs tâches, tous les créateurs auront une IA avec laquelle leur communauté pourra s'engager, toutes les entreprises auront une IA avec laquelle leurs clients pourront interagir pour acheter des biens et obtenir de l'aide, et tous les développeurs disposeront d'un modèle open source à la pointe de la technologie pour créer leurs projets. »
À noter que chez Mark Zuckerberg, l’IA d’entreprise est une dérivée de l’IA de consommation. La trajectoire est claire: fabriquer des modèles avec toujours plus de paramètres et une inférence la plus rapide, la moins coûteuse possible (puces maison). Compter sur la force de distribution (en milliards de personnes) pour les amortir. Les autres Big Tech sont dans la même ligne: réaliser des modèles très performants pour leurs propres produits et des modèles inférieurs, pas cher pour les entreprises. Avoir des clients en plus est toujours bienvenu. C’est ainsi que Google a lancé sa gamme open source Gemma, avec 2 et 7 milliards de paramètres; Microsoft a dévoilé Phi-2 en décembre 2023, un modèle à 2,7 milliard de paramètres. Le petit modèle (SLM) est facile à entrainer et peu consommateur en GPUs.
Produits d’entreprise
Les produit d’entreprise dans l’intervalle vont suivre une voie plus modeste (produits de niche comme Github Copilot). Les services informatiques et sociétés technologiques ont été échaudés par le krach de 2022 et vont être prudents sur les investissements: on préférera nettoyer les données plutôt qu’utiliser les modèles derniers cris. Et sur les modèles déjà amortis, on privilégiera les RAGs (permet d’intégrer les données de l’entreprise à un modèle) à l’entraînement plus coûteux des modèles sur les données de l’entreprise. Deux problèmes vont se poser et ralentir l’adoption dans le monde de l’entreprise:
-les hallucinations. Comment reconstruire son entreprise à partir d’un modèle qui peut halluciner ?
-la sécurité des données. Quel risque à confier ses données à ChatGPT ? Le cloud a été ralenti au début des années 90 par cette même préoccupation.
Les Big Techs sont prudentes sur le marché de l’entreprise. D’après The Information, le 12 mars 2024:
Plusieurs dirigeants, chefs de produits et vendeurs des principaux fournisseurs de services en nuage, tels que Microsoft, Amazon Web Services et Google, ont également déclaré en privé que la plupart de leurs clients étaient prudents ou "réfléchissaient" avant d'augmenter leurs dépenses pour de nouveaux services d'IA, compte tenu du prix élevé de l'exploitation du logiciel, de ses lacunes en termes de précision et de la difficulté à déterminer la valeur qu'ils en retireront.
Cette mise en garde met en lumière une question que se posent les investisseurs et les dirigeants d'entreprises dans les domaines de la technologie et des affaires : Quand les entreprises verront-elles les avantages tant vantés des logiciels qui visent à automatiser les tâches humaines répétitives ?
C’est pourquoi les petits modèles qui peuvent fonctionner en local ( y compris avec une architecture cloud) , focalisés sur les flux de travail les plus substituables par de l’intelligence artificielle vont être privilégiés. On peut imaginer une industrie se créer autour de flux de travail automatisés par l’IA générative sous forme de micro-services. Copy.AI par exemple propose des flux de travail dopés par l’IA générative standards qu’on branche en API sur les données de l’entreprise. De même, Nvidia lors de sa dernière Keynote a lancé les NIM (Nvidia Inference Microservices), des flux de travail standard fonctionnant bien évidemment sur des puces d’inférence Nvidia. Il est probable que la majorité des sociétés SAAS intègrent des LLM pour proposer leur propres micro-services. Mais au delà ?
Il n’y a pas de révolution immédiate à attendre. La plupart des emplois consistent à orchestrer plusieurs flux de travail. Ces emplois seront plutôt facilités par l’IA générative que supplantés, car l’IA générative de base (SLM) n’aura pas cette capacité d’orchestration. L’exception sera l’emploi correspondant à un flux de travail unique comme par exemple la personne qui répond au téléphone.
Les entreprises vont également essayer d’ajouter de l’IA générative à leurs produits pour les mettre en valeur. La aussi, n’y a t’il pas un risque qu’elles se lancent dans la course de la Reine Rouge vue dans une précédente lettre ? Auquel cas l’IA devient un coût pour les entreprises et un bénéfice pour le consommateur ?
Sommes nous aujourd’hui sur le pic des attentes exagérées concernant l’entreprise ? C’est ce que semble penser AWS. Toujours d’après The Information:
AWS, le plus grand vendeur de serveurs en nuage, a récemment confronté ses vendeurs à la réalité de la technologie. Chirag Dekate, analyste du cabinet d'études Gartner, a déclaré au personnel de vente d'AWS lors d'un événement annuel de lancement il y a deux semaines que l'industrie était au sommet du "cycle d'engouement" autour des grands modèles de langage et d'autres formes d'IA générative. Selon un employé qui a assisté à la présentation, il s'attend à ce que l'engouement se transforme en un "creux de désillusion" au cours de l'année à venir, à mesure que les clients se rendent compte des limites de la technologie. Il s'attend toutefois à ce que les clients finissent par l'adopter à grande échelle.
La construction du cloud IA
Le produit de consommation intégré est la poule aux œufs d’or, il concentrera les profits attractifs, car il ne sera jamais assez bon pour le consommateur; l’asymptote de progression est oblique et non pas horizontale. Ses ambitions seront supérieures au produit d’entreprise, quitte à halluciner un peu plus et confier d’avantage ses données; les particuliers sont moins sensibles à ces travers que les entreprises. Il nécessitera les modèles les plus performants, d’où le positionnement des Big Tech sur OpenAI, Gemini, Anthropic et Llama. La constitution d’un cloud IA performant en sera la condition nécessaire. Là aussi se joue une lutte pour l’intégration et la conservation des produits attractifs ! Mon prochain article sera consacré à la construction de ce cloud IA.
Bonne semaine,
Hervé