


Puces: Intel est-il hors jeu ?
Le come-back de la loi de Moore.
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
De Znet.fr (17 décembre 2019):
Intel vient de réaliser l’une de ses plus importantes acquisitions en matière d’intelligence artificielle en s’emparant d’Habana Labs pour 2 milliards de dollars. Cette entreprise israélienne fabrique un processeur programmable nommé HLS-1 Gaudi destiné aux tâches d’apprentissage profond sur les datacenters. Cet accélérateur est censé produire un débit d’entrées/sorties 4 fois supérieur aux systèmes conçus à partir de GPU.
“Habana dope nos offres d'intelligence artificielle pour le centre de données avec une famille de processeurs haute performance pour l'entraînement et un environnement de programmation basé sur des standards pour répondre à l'évolution des charges de travail d'intelligence artificielle", commente Intel. Habana Labs continuera à fonctionner indépendamment avec son équipe de direction actuelle et sera intégrée au Data Platforms Group d’Intel. Le fondeur dit s’attendre à générer 3,5 milliards de dollars de revenus liés aux activités d’intelligence artificielle cette année, ce qui représenterait une progression annuelle de plus de 20%. (Eureka Presse)
Il était une époque où Intel dominait totalement l’industrie des puces. Le centre de l’univers technologique était le PC, dont le noyau, la pièce essentielle était le microprocesseur x 86. Le doublement de la densité des transistors tous les 2 ans (Loi de Moore ) alimentait la demande de PC qu’il fallait sans cesse renouveler pour se mettre à niveau. Le système d’exploitation devait s’adapter à ou anticiper cette nouvelle puissance. Tout programme pour fonctionner devait être compatible avec l’architecture x86 et l’OS qui allait avec: Windows. Il s’est donc institué un duopole pour se partager le cerveau du PC: Intel pour le hardware et Microsoft pour le software. Intel intégrait la conception, la fabrication et l’ordonnancement du bloc microprocesseur, les autres éléments du hardware étant modulaires. Évidemment, les marges étaient pour Intel et Microsoft, les fabricants de PC étant laissés dans la poussière.
La hantise d’Andy Grove, Cofondateur d’Intel, exprimée dans son livre Seuls les paranoïaques survivent publié en 1988 pour la première fois était que l’intelligence soit transférée dans le réseau…il fallait donc qu’Intel se batte pour que les microprocesseurs soient toujours plus puissants et restent au niveau local. Andy Grove avait bien prévu la révolution copernicienne du cloud, mais comptait sur la loi de Moore pour l’éviter. La loi de Moore ralentissant dans les années 2000, la course à la puissance s’est arrêtée, laissant place à d’autres innovations.
Comment Intel s’est fait dépasser
Le marché a d’abord éclaté en deux:
Le smartphone a suivi l’internet, et décollé à partir de l’invention de l’iPhone en 2007. La puce n’était plus l’élément essentiel du smartphone, c’était plutôt l’intégration du software et du hardware dans une petite pièce de matériel. Le premier processeur de l’iPhone était un Samsung d’architecture ARM (architecture simplifiée par rapport à celle de l’x86). Apple avait banalisé le processeur: ce qui importait était l’économie de la batterie, pas la puissance, qui était largement suffisante avec les puces ARM. Les fabricants de téléphones Androïd on suivi le modèle. La technologie CISC de l’x86 était surdimensionnée. Le smartphone à éclipsé le PC avec une base installée trois fois plus importante aujourd’hui, les puces ARM ont pris le pas sur les x86 dans les petits appareils.
En complément des smartphones, des applications multiples se sont créées, hébergées dans des data centers. On peut citer Box ou Salesforce pour les applications entreprises. Ces data centers utilisaient des puces x86, du type Intel ou AMD, plus puissantes que les puces ARM et surtout compatibles avec les programmes conçus pour tourner sur PC et smartphones. Au final, la demande pour les microprocesseurs Intel a augmenté mais sur une clientèle plus concentrée et qui peut utiliser d’autres types de puces également (FPGA, ASIC). La part des serveurs dans le chiffre d’affaires est monté de 38% à 48% entre 2014 et 2018. La relation de pouvoir d’Intel s’en trouve affaiblie ainsi que sa marque. En arrière plan, AMD fait aussi bien l’affaire et d’autres architectures battent le CPU sur certaines fonctionnalités.
La théorie de la modularité, édictée par Clayton Christensen permet de comprendre l’évolution de cette industrie. Dans une chaîne de valeur, le profit va vers les taches interdépendantes, intégrées qui demandent un savoir faire spécial pour combler l’écart entre l’offre et la demande. Pour les autres taches, où offre et demande sont équilibrées, des pièces standard suffisent. Quand une tâche intégrée devient standard, l’intégration de déplace à un autre endroit de la chaîne. L’intégration des composants autour du microprocesseur (SOC) a longtemps constitué ce qui était le plus demandé dans un ordinateur (diminution par 2 du coût de l’arithmétique tous les 18 mois). Le reste des pièces était modulaire, sans valeur ajoutée (Le PC lui même, la mémoire, le disque dur, etc.). Le smartphone a bousculé cette chaîne de valeur: ce qui était demandé était l’orchestration du software et du hardware dans un tout petit espace, la puissance de calcul était bien suffisante et pouvait être modularisée). Le profit est allé chez celui qui faisait au mieux cette intégration: Apple.
Tout ceci pour expliquer qu’Intel a été victime d’une deuxième rupture dans les serveurs: L’intégration des serveurs et des applications est vite devenue lourde, elle obligeait les producteurs de software à mobiliser des ressources inutiles en serveurs pour servir leurs clients. AWS a été le premier à casser cette intégration. proposant ses serveurs sous forme d’abonnement. Dès lors, les fournisseurs d’applications pouvaient proportionner les ressources en hardware à la demande et éviter de dépenser en amont des montants significatifs de capital. L’effet a été de multiplier les applications tournant sur le cloud. Mais pour Intel, c’était un nouveau coup dur: le cloud tout entier devenait le point d’intégration, le tuyau d’oxygène de l’internet. La conséquence est une concentration encore renforcée de clients pour Intel et la possibilité de se faire complètement déplacer par des puces aux spécificités de l’opérateur cloud. C’est ainsi qu’AWS a lancé sa propre puce ARM Graviton et Google sa puce ASIC TPU. De même les FPGA (puces reprogrammables) arrivent dans le cloud pour gérer des besoins spécifiques tels que flux d’information par exemple. Pour couronner le tout, l’intégration d’Intel autour du design et de la fabrication est aussi en train de sauter: cette intégration très efficace pour le PC, l’avait ralenti dans ses efforts mobile: il n’apportait pas de valeur par rapport à l’usine TSMC sur les puces ARM. Mais maintenant TSMC a beaucoup amélioré son outil de fabrication et grave en 7nm alors qu’Intel vient juste de passer au 10 nm. Cela signifie que l’intégration d’Intel sur le CPU x86 est branlante: AMD peut faire mieux en sous traitant la fabrication à TSMC. Il faut noter que ces développements ne se voient pas trop dans les chiffres d’Intel car les opérateurs cloud sont très demandeurs de CPU du fait de leur hyper croissance.
Résumons nous:
Intel est quasi inexistant dans les smartphones, le marché dominant
Intel compense sur le marché des serveurs mais peut se faire plus facilement concurrencer dans le cloud. L’architecture x86 ne tient que grâce à l’historique des programmes développés sur cette architecture ayant basculé sur le cloud. La containérisation des programmes les rendent compatibles toutes architectures. C’est un cauchemar pour Intel !
Intel perd la supériorité de son appareil de production. TSMC grave en 7nm contre 10 nm pour Intel.
Et par ailleurs:
TSMC prend en charge la fabrication, libérant la créativité des concepteurs de puces.
De nouveaux usages se développent autour du graphisme et de l’IA. Le CPU rentre en concurrence avec le GPU, l’ASIC et le FPGA.
Le marché est donc très ouvert. Quelles sont les tendances principales ?
Vers une spécialisation
Intel a inventé la puce à tout faire, le CPU (Central Processing Unit). Cette puce a le mérite de pouvoir réaliser des opérations complexes. En ajoutant des cœurs, la puce permet de faire des opérations simultanées: 2 cœurs, 2 opérations. Son inconvénient comme toute usine à gaz est la déperdition d’énergie pour le traitement d’opérations très typées.
L’internet nous amène un monde d’abondance, dans lequel nous n’avons pas à faire de compromis. Si une offre nous satisfait à 100%, nous prenons, sinon nous rejetons. C’est le consommateur qui fait la loi, et par extension l’entreprise qui en est le plus proche (Amazon, Facebook, etc.). Nous n’avons plus à faire de compromis, les points de passage obligés fourre-tout disparaissent. Toute l’infrastructure sous-jacente s’est modelée sur la nécessité de répondre parfaitement aux besoins du client (qui peut aussi être une entreprise). Les applications sont de plus en plus précises et efficaces à répondre à un besoin précis, elles y investissent toutes leurs ressources. Cela donne alors un sens aux fournisseurs de cloud qui gèrent toute la complexité sous-jacente à ces applications (infrastructure,OS, réseau, etc.). Dans la théorie de Christensen, les fournisseurs cloud intègrent la complexité. Ils ont donc l’avantage concurrentiel maximum. Les applications se branchent sur le cloud en « plug and play » et deviennent modulaires. Leur avantage concurrentiel est mince; quid d’un concurrent qui répond également précisément au même besoin ? Zoom a déplacé Skype, Stripe peut déplacer Square, etc. Les puces sont un moyen pour les applications de répondre le plus efficacement à leur fonctionnalité. L’internet des objets est la suite logique de cette spécialisation où chacun de ces objets applique un automatisme fonctionnel. Le marché des puces suit le marché des applications dans sa spécialisation. Comme le cloud a permis la prolifération d’applications de toute sorte, TSMC permet la prolifération de puces de toutes sortes.
TSMC, la fabrique à puces
TSMC est aux puces, ce qu’AWS est aux applications, l’infrastructure qui rend possible l’abondance. Il y a une dizaine d’année , les producteurs de puces étaient légion: Intel, AMD, IBM , Panasonic, Samsung, Texas Instrument, Fujitsu, Toshiba, ST et Renasas concevaient et fabriquaient leurs puces en 45 nm, alors que TSMC et UMC ne faisaient que le travail de fonderie. L’intégration a largement sauté pour deux raisons:
Intégrer conception et fabrication permet de faire des produits très performants mais la conséquence est le manque de souplesse. Quand la demande de variété l’emporte sur la demande de performance, l’intégration atteint sa limite et peut se faire déplacer. On a vu dans l’offensive Cybertruck combien la plate-forme Tesla contraignait les modèles (par exemple le modèle X devait reprendre le bloc moto propulseur du modèle S, ce qui n’est pas idéal pour un SUV).
La fragmentation de la demande est de plus en plus difficile à amortir sur des fonderies (usines à puces) aux besoins en capitaux de plus en plus énormes (inversement proportionnel à la taille du transistor). Le prix d’une fonderie dernière génération est de près de $ 15 milliards. L’intégration demande un volume considérable que peu de concepteurs de puces peuvent se permettre, seulement les généralistes.
Les producteurs intégrés ont dû lâcher: AMD le premier qui a fait un spin off de son outil de fabrication Global Foundries en 2009, lequel a repris deux ans plus tard la fonderie d’IBM. Panasonic et Fujitsu ont abandonné le modèle intégré en 2013 en fusionnant leur activité semi-conducteur, Toshiba a vendu ses fonderies à un consortium incluant Apple en 2016, etc. L’internet a libéré l’intelligence: prisonnière du PC, elle s’est répandue dans le réseau, se regroupant pour former une super-intelligence dans le cloud et des dépendances aux extrémités (edge computing). Les puces sont devenues aussi variées dans leurs spécificités que les applications les utilisant. Une prolifération de puces et d’assemblages de puces se sont créées sur des architectures existantes le plus souvent, éclipsées autrefois par Intel. Les puces graphiques se sont développées pour le traitement de l’image. Les GPU ont été utilisés pour d’autres fonctions où leurs cœurs multiples étaient un atout: minage des crypto-monnaies, IA. Ces GPU n’étaient pas parfaites pour ces autres fonctions, ayant été conçues pour les fonctions du traitement de l’image, leur précision graphique était excessive par rapport à de nombreux besoins. Les ASIC se sont développées (application specific integrated circuits), pour des besoins spécifiques, enfin les puces reprogrammables ou FPGA pour parer l’inconvénient des ASIC, c’est à dire les petites séries. Pour répondre aux besoins spécifiques ces puces variées sont ensuite combinées dans des SOC (systems on a chip). Intel ne pouvait répondre à une telle variété de besoins qui dépassaient la performance pure; de plus, les petites séries que ces besoins engendraient nécessitaient de casser l’intégration trop coûteuse. Les concepteurs de puces graphiques ATI et Nvdia ont adopté le modèle sans usine, suivis par les concepteurs de puces de smartphone (Qualcomm, Apple), TSMC fabriquant du ARM, et enfin les concepteurs de puces de toute sorte aussi bien dans le cloud qu’en edge computing. TSMC est devenu l’usine à fabriquer toutes ses puces, dépassant largement ses concurrents comme UMC et Global Foundries. La société a bon an mal an 50% du marché de la fonderie, loin devant Samsung. TSMC permet la floraison de puces tout comme AWS permet la prolifération d’applications, en prenant à sa charge une grande partie des coûts fixes. L’écosystème est extrêmement dangereux pour Intel, mais a malgré tout une faille que ce dernier peut exploiter.
La faille de l’écosystème TSMC/concepteurs sans usines
Les concepteurs de puces se battent pour trouver des architectures/designs de plus en plus adaptées aux différents besoins issus de l’abondance de l’internet. Les fournisseurs de cloud conçoivent leurs propres puces et les proposent dans leurs offres commerciales: AWS a ainsi développé une ligne de puces ARM pour ses serveurs (Graviton 1 et 2) et propose un abonnement cloud bon marché. Google a créé sa propre puce d’intelligence artificielle TPU qui permet de traiter des données massives à faible consommation énergétique, damant le pion des puces graphiques GPU sur les traitements de masse. Google peut ainsi proposer une offre IA bon marché aux entreprises. Pour les traitements moins importants, les puces GPU continuent à faire l’affaire, bien qu’elles risquent aussi d’être considérées comme des usines à gaz pour le traitement de l’IA dans le futur, notamment quand il n’y a pas reconnaissance d’images. Ainsi Apple a introduit avec l’Iphone X son neural Engine (ANE), un co-processeur supposé accélérer l’IA par un facteur de 9 avec 10% de l’énergie d’un GPU. Amazon utilise les puces Syntiant pour rendre intelligent les accessoires liés à Alexa. Ces puces consomment très peu d’énergie et sont adaptées à la reconnaissance vocale.
Il y a un double problème à terme lié à cette floraison d’architectures différentes:
On conçoit des puces pour des séries de plus en plus réduites. Or même si le coût de fabrication peut être transformé en coût variable grâce à TSMC ou Samsung, le coût de conception est fixe et non négligeable. Or ce dernier a tendance à flamber de manière inversement proportionnelle à la taille de la gravure:
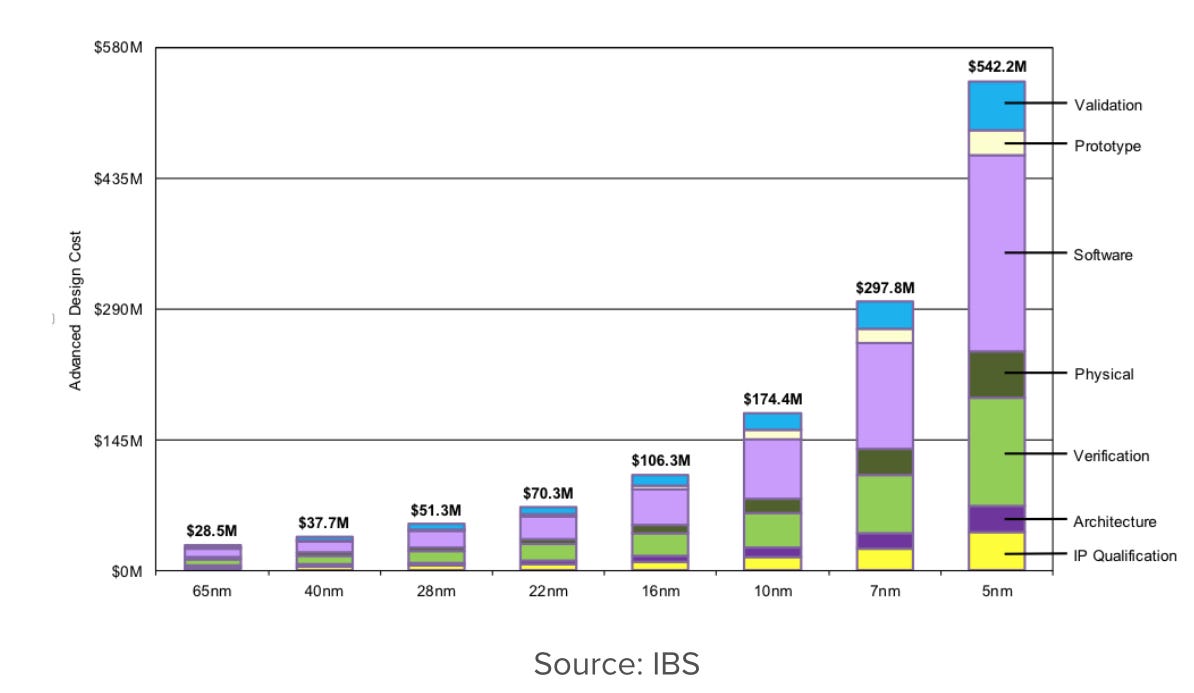
Le prix de la conception a triplé du 16 nm au 7 nm.
Le prix d’une fonderie subit le même phénomène d’escalade du coût de l’investissement. UMC a lâché la course à 12 nm, Global Foundries à 10 mn. On estime le prix d’une fonderie 7 nm à $14 milliards. Seuls les objets produits en grandes séries ou les clouds peuvent se permettre de tels coûts.
La conséquence inéluctable est une forte augmentation du coût des puces, notamment des puces les plus finement gravées, celles qui sont le plus utilisées en edge computing. La spécialisation a des limites qui pourraient bien être atteintes dans les années qui viennent. En temoigne le peu d’investissement en VC dans le edge computing:
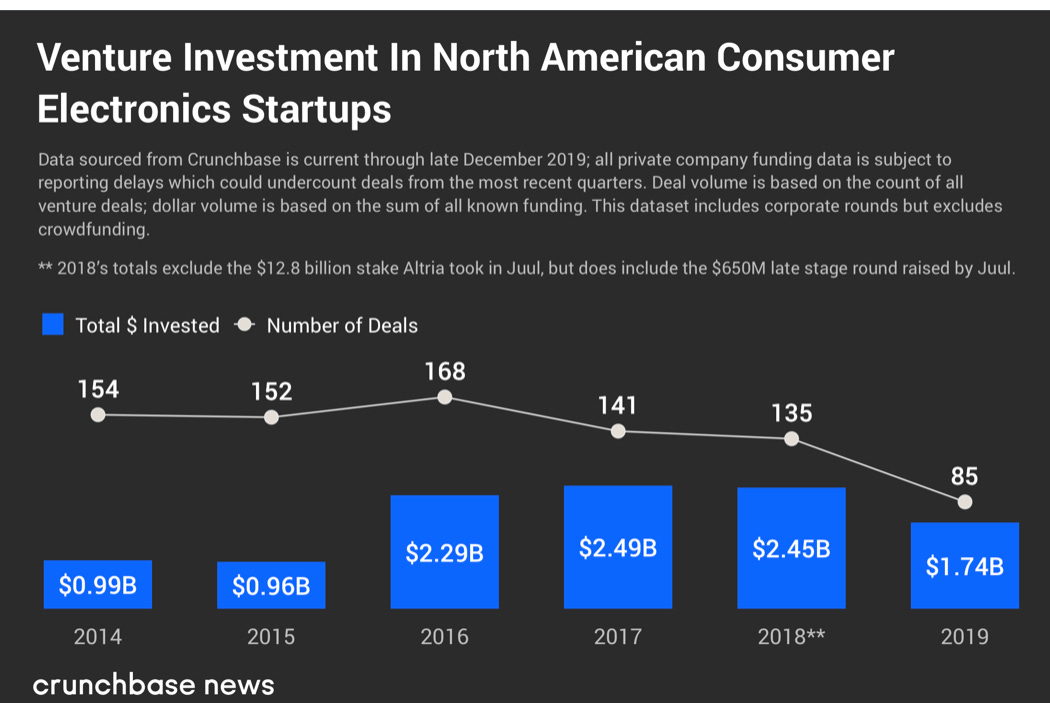
Les limites sur la performance à la périphérie devront être compensées par d’avantage de performance dans le cloud, surtout si l’on souhaite que les prévisions de l’IA soient suffisamment fiables pour automatiser des actions (robotique). C’est là où Intel peut regagner son avantage à condition de trouver le facteur unifiant, source d’économies d’échelle.
Intel fait levier sur son intégration
Le business d’Intel est à maintenant 50% dans les data centers. Le standard x86 (principalement Intel et AMD) est requis pour sa compatibilité avec les programmes historiques. AMD a largement comblé son retard avec Intel grâce à l’appui de TSMC. Intel cherche un moyen pour faire fonctionner la loi de Moore qui l’avait propulsé dans les années 90. Car la loi de Moore demandant de la vitesse, donc du feedback favorise l’intégration conception/fonderie.
D’après Open AI, la puissance de calcul développée pour l’IA double tous les 3 à 4 mois. La loi de Moore est enfoncée:
Nous publions une analyse qui montre que depuis 2012, la quantité de calculs utilisés dans les plus grandes formations d'IA a augmenté de façon exponentielle avec un temps de doublement de 3,4 mois (par comparaison, la loi de Moore avait une période de doublement de 2 ans)[1]. Depuis 2012, cette mesure a augmenté de plus de 300 000 fois (une période de doublement de 2 ans ne donnerait qu'une augmentation de 7 fois). Les améliorations en matière de calcul ont été un élément clé des progrès de l'IA, aussi longtemps que cette tendance se poursuivra, il vaut la peine de se préparer aux implications des systèmes qui sont bien au-delà des capacités actuelles.
Or c’est la loi de Moore et son tempo qui explique en grande partie le succès d’Intel: les logiciels et les CPU étaient dans une course à la puissance, éclipsant d’autres innovations possibles: les logiciels prévoyaient à l’avance la loi de Moore dans leurs instructions et Intel faisait plus que rattraper avec de nouvelles puces, adaptant ses fonderies et obligeant les éditeurs de logiciels à anticiper encore, etc.
Intel veut redevenir un point d’intégration et il pense que l’intelligence artificielle, un marché nouveau et en pleine expansion peut lui en donner l’occasion. Les puces d’apprentissage sont le facteur unifiant car constituant le goulot d'étranglement de l’IA: tout programme d’intelligence artificielle demande un apprentissage avec des données de plus en plus massives qui sont logées dans des centres de données. Les puces d’apprentissage demandent une puissance colossale pour le traitement des données, bien plus que les puces d’inference qui réclament surtout une très faible latence et seront réparties entre centre (cloud) et périphérie (edge). L’écosystème TSMC/fabless est plus lent à réagir face à un contexte mouvant comme la loi de Moore: comme à la guerre, c’est plus dur de se coordonner quand on est nombreux. La loi de Moore cette fois dépasse la taille des transistors et s’applique à la combinaison et au placement des éléments contribuant à la fabrication de la puce. Intel veut regagner les centres de données en leur fournissant une pièce essentielle d’IA, multi-usage, pouvant créer un effet d’échelle. Intel par l’achat d’ Habana Labs s’intéresse à la puce d’apprentissage Gaudi. la Gaudi est nettement plus performante qu’une puce GPU à taille identique avec une excellente capacité de mémoire et une consommation énergétique limitée. Elle a surtout la capacité d’être alignée en séries avec un accès standardisé pour les programmes. Elle est donc idéale pour entraîner tout algorithme d’IA pour des données massives dans les centres de données et le cloud (plug and play). On peut facilement adapter la quantité à la charge de travail et elle est compatible tout langage de ML.
La force de cette puce ASIC est de pouvoir faire un calcul matriciel énorme, un peu moins précis qu’une GPU, mais avec une bien meilleure efficience énergétique. Intel espère battre aussi la TPU de Google, elle même en avance sur les GPU, car son approche modulaire pourrait la freiner dans un contexte d’hyper croissance. Dès lors Intel espère pouvoir imposer un point d’intégration pour les centres de données et les clouds.
Il est peut être moins intéressant pour Intel d’être un point d’intégration pour des gros clients plutôt que pour les nombreux acheteurs de PC. Les clouds ont en effet plus de levier pour négocier. Cependant, alors que la modularité a complètement gagné l’industrie, Intel avec son outil intégré peut se retrouver le candidat idéal pour répondre à une demande exponentielle de puissance de calcul délivrée avec le moins de consommation énergétique possible. Il n’y a pas de supériorité de l’intégration sur la modularité, tout est une question de contexte. Mais quand tout le monde fait zig, il est peut être judicieux comme Intel de faire zag.