


Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.
On se souvient de la fameuse et prémonitoire proclamation de Marc Andreessen en 2011: software is eating the world. Qu’en est-il aujourd’hui ?
Ce texte est la suite logique de IA: l’enlisement. Il y a deux tendances claires:
l’IA poursuit le travail entamé par le logiciel qui est d’envahir les moindres recoins de l’économie: les routines de prédiction sont associées aux logiciels pour anticiper nos besoins dans toutes les circonstances. Ces routines doivent devenir de plus en plus fiables, pour retenir l’attention de l’utilisateur; le combat est loin d’être gagné.
le modèle économique de l’IA n’est pas aussi rentable que celui du logiciel. Ce dernier repose sur des frais fixes de départ suivis d’un coût marginal quasi nul, incitant à une forte expansion horizontale avec des marges brutes de 80/90%. Le premier engendre des coûts variables importants, en plus des coûts fixes de départ, nécessaires pour améliorer la qualité de la prédiction. Les marges tombent alors à 60% maximum, le logiciel tombe de son piédestal. Pour battre un concurrent à la prédiction, il faut traiter plus de données (nécessite des hommes pour les interprêter), plus rapidement (nécessite de la puissance de calcul) et plus efficacement (nécessite des mathématiciens). Malheureusement pour les concepteurs de logiciel, il leur faut pratiquer la course de la Reine Rouge dans Alice au Pays des Merveilles: toujours plus vite pour revenir au point de départ ! Dans leur cas c’est toujours plus de frais variables et toujours moins de marges brutes pour des prédictions plus fiables que le compétiteur.
Prenons la question sous un autre angle: quand Marc Andreessen a fait sa fameuse proclamation en 2011: “software is eating the world”, l’IA était encore dans les limbes, l’apprentissage profond au démarrage. Le logiciel était alors et est resté tout au long des années 2010 un facilitateur de taches, un serviteur pas cher obéissant au doigt et à l’œil (à quelques bugs près ). La demande était très forte: en faisant le boulot à notre place dans de nombreux cas, le logiciel nous libérait du temps à utiliser de manière plus productive ou plus intéressante. C’est l’époque Adobe, SAP, Dropbox, etc. Dans cette phase pré IA on demandait au serviteur d’obéir et de répondre aux demandes: il était évalué à la qualité de la réponse. Une société de logiciel qui faisait le job prenait le leadership et grâce aux économies d'échelle laissait les compétiteurs potentiels dans la poussière. C’était simple: un serviteur (logiciel) pour chaque type de tâche. L’IA a tout compliqué: on demande maintenant non seulement que le serviteur fasse le job mais aussi qu’il l’anticipe. Cette fois le serviteur est évalué sur la qualité non seulement du job mais aussi de l’anticipation. Il y a donc un double critère d’évaluation qui rend la concurrence potentielle plus intense et le modèle moins intéressant.
Les goulots d’étranglement ont changé en passant de la phase 1 (logiciel) à la phase 2 (logiciel et IA). En phase 1, les développeurs étaient le chaînon manquant. En phase 2, ils le restent mais sont rattrapés par les semi-conducteurs. Revenons sur ces questions:
phase 1: la forte demande sur les logiciels crée une pénurie de développeurs. L’offre ne peut s’ajuster au même rythme que croît la demande (profession nécessitant une expertise élevée longue à acquérir). Pour y pallier, la mutualisation se développe au travers de l’open source. La demande est soutenue pour les semi-conducteurs mais l’offre suit. Les usages se diversifient, le mobile supplante le PC en fin de course, Intel perd son monopole de l’architecture CISC au profit de l’architecture RISC simplifiée et moins consommatrice d’énergie utilisée pour les petits appareils et des GPUs adaptés aux calculs simples mais puissants. La loi de Moore appliquée à la puissance de la puce plutôt qu’à la taille du transistor continue de s’appliquer grâce aux prouesses réalisées sur l’architecture. La plupart des acteurs s’en sortent, il y a du pain pour tout le monde; le traditionnel cycle des semi-conducteurs s’atténue. Mais on ne peut parler de pénurie.
phase 2: la frénésie de demande se poursuit sur le logiciel imprégné d’IA. La pénurie de développeurs continue. Mais cette fois la demande de puissance de calcul explose à la hausse, au fur et à mesure que la course de la Reine Rouge se met en place. Tous les 3/4 mois, la demande de traitement de données double pour entraîner les algorithmes, alors que la loi de Moore ne prévoit un doublement que tous les deux ou trois ans. La progression de GPT, le dispositif d’intelligence artificielle générale d’OPEN AI l’exprime bien: la version GPT-2 créée en 2019 intégrait 1,5 milliard de paramètres, la version GPT-3 sortie en juillet 2020 175 milliards. La pénurie de puces intelligentes devient une réalité. Conséquences ?
Puissance: le chaînon manquant
La loi de Moore consiste en l’augmentation de la densité des transistors dans les puces par un facteur de 2 tous les deux à trois ans. On annonce régulièrement la fin prochaine de la loi de Moore mais à chaque fois, les limites sont repoussées. La loi de Moore tient et d’après Jim Keller, le maître architecte en puces, pour encore 50 ans. D’après lui, l’augmentation de la densité n’est pas le fruit d’une invention géniale à chaque fois mais de mille inventions concomitantes sur les matériaux, la gravure, l’agencement, les connexions, etc. Une puce est extrêmement complexe. Chaque invention suit une loi de progression logarithmique mais la combinaison est exponentielle. La loi de Moore est un bon baromètre de la progression de la puissance des puces. Ou tout au moins elle l’était jusqu’au milieu des années 2000: puis la puissance n’a plus suivi et il fallut inventer une astuce: rajouter des cœurs pour compenser. Le problème est qu’on ne peut rajouter des cœurs éternellement. La loi de Moore ne s’applique pas aux cœurs. On voit le problème: l’industrie peut fournir au mieux un doublement de la puissance tous les deux/trois ans, ce qui est complètement insuffisant par rapport à l’augmentation de la demande de puissance liée à l’entraînement mais aussi à l’inférence des systèmes d’IA. Il va donc falloir non seulement utiliser la puissance existante qu’elle soit sur CPU, GPU ou ASIC mais aussi aligner les puces pour gagner de la puissance pure et suivre la demande. Les opérateurs cloud seront les mieux placés pour offrir la capacité nécessaire dans les meilleures conditions de prix, du fait de leur échelle.
La contrainte des développeurs
Les puces traditionnelles tant CPU que GPU n’ont pas été conçues pour la prédiction mais pour l’exécution. Faute de mieux, ce sont quand même elles qui ont été utilisées pour entraîner et déployer les algorithmes d’IA et elles occupent le terrain aujourd’hui. Le CPU exécute des tâches complexes et variées en séquentiel avec une bonne mémoire d’accès immédiat alors que le GPU exécute des tâches simples en parallèle, mais manque de mémoire. Ce dernier est un accélérateur, Il n’est pas autonome et à tout de façon besoin d’être accompagné d’un CPU. Les deux types de puces ont leurs avantages et inconvénients pour traiter de l’IA. Le CPU a une capacité d’adaptation plus importante que le GPU et peut être amorti sur des tâches variées. Il sera moins cher que le GPU mais moins efficace sur des données massives (apprentissage profond). Aussi les deux types de puce ont occupé le terrain, c’est à dire que les développeurs ont adopté leurs architectures. C’est un point fondamental pour la suite: du fait de la pénurie de développeurs, on ne peut se permettre de changer d’architecture car reprogrammer l’historique et former les développeurs monopoliserait trop de ressources précieuses. C’est un avantage énorme pour les existants et en particulier les leaders d’une architecture, en particulier Intel pour le x86, ARM pour la technologie RISC, Nvidia pour les GPU, Xilinx pour les puces programmables, etc. Nvidia par exemple chiffre 2 millions de développeurs sur son architecture, un doublement en deux ans. La révolution est trop chère, vive l’évolution ! C’est pourquoi on enterre un peu vite Intel qui a perdu son avance sur le processus de fabrication: Intel à un gros avantage: la majorité des programmes ont été écrits pour l’architecture x86 qu’il domine. C’est un levier extraordinaire pour rebondir. On avait de même enterré Microsoft il y a quelques années du fait de son obsession à tout centrer sur Windows. La grande force de Microsoft était Office, présent dans toutes les entreprises, très difficile à déplacer et dont Microsoft a utilisé la présence pour proposer d’autres prestations, le cloud notamment. Avoir un pied dans l’entreprise sans pouvoir être dérangé est extrêmement précieux. Le point fort d’Intel n’est pas la fabrication mais x86. Avoir un pied dans le monde des développeurs sans vraiment pouvoir être dérangé car le temps presse est aussi précieux.
La contrainte des opérateurs cloud
La contrainte de puissance et des développeurs se transforme en contrainte de mutualisation. Le gaspillage n’est plus possible. ll faut mutualiser la mémoire (le stockage), la puissance (microprocesseurs) et le développement (logiciels): une approche modulaire est de mise, créant des passerelles entre les acteurs. Le point d’intégration selon la loi de Clayton Christensen devient le cloud tout entier, c’est lui qui permet de résoudre le problème de capacité. Les opérateurs cloud se doivent de fournir l’abondance, donc toutes les architectures, en fonction des besoins des clients. Mais plus que cela, il leur faut faire tourner les applications qui leur sont confiées avec le meilleur mix de puissance pour pouvoir optimiser le prix du service. Le GPU est très efficace certes mais pour des calculs parallèles, très onéreux et consomme beaucoup d’énergie. Il n’est pas aussi versatile qu’un bon vieux CPU qui peut s’adapter à de multiples usages, nativement calcule en séquence pour exécuter des tâches mais peut se transformer tel un caméléon pour faire de la prédiction. La Start up Neural Magic, fondée en 2018, s’est donnée pour objectif de transformer un CPU en GPU pour justement pouvoir traiter de l’IA pas cher:
Neural Magic, une start-up fondée par deux professeurs du MIT, qui ont trouvé un moyen de faire fonctionner des modèles d'apprentissage sur des processeurs de base CPU, a annoncé aujourd'hui un investissement initial de 15 millions de dollars.
Comcast Ventures a mené la ronde, avec la participation de NEA, Andreessen Horowitz, Pillar VC et Amdocs. L'entreprise avait déjà reçu 5 millions de dollars en préamorçage, ce qui porte à 20 millions de dollars le total des fonds levés à ce jour.
La société a également annoncé un accès précoce à son premier produit, un moteur d'inférence que les scientifiques peuvent faire fonctionner sur des ordinateurs équipés de processeurs CPU, plutôt que sur des puces spécialisées comme les GPU ou les TPU. Cela signifie qu'il pourrait réduire considérablement le coût associé aux projets d'apprentissage machine en permettant aux scientifiques d'utiliser du matériel de base.
L’idée est de pouvoir utiliser toutes les ressources existantes pour pouvoir traiter de l’IA et ainsi en baisser le prix moyen tout en traitant les plus gros volumes possibles.
Les opérateurs cloud vont ainsi concentrer l’essentiel de la puissance et celle ci profitera à tous les acteurs capables d’en fournir. De Semiconductor Engeeniering le 25 juillet 2019:
"Vous avez lu que les centres de données peuvent consommer 5 % de l'énergie aujourd'hui", explique Ron Lowman, responsable du marketing produit pour l'intelligence artificielle chez Synopsys. "Cela peut aller jusqu'à plus de 20 %, voire jusqu'à 40 %. Il y a une raison spectaculaire de réduire la consommation d'énergie des puces pour le centre de données ou de le déplacer vers la périphérie".
De cette débauche de puissance, une partie sera déversée en périphérie, que ce soit pour des raisons techniques (latence), de sécurité (données restent locales) ou politiques (réchauffement climatique). Les matériels périphériques seront en sous-capacité flagrante par rapport aux besoins. Les gagnants seront ceux qui réussiront à optimiser la complexité: espace, consommation d’énergie et puissance.
Les semis en périphérie
L’approche modulaire horizontale valable quand on veut mutualiser est là un handicap: c’est une taille unique pour tous, alors qu’en périphérie, il faut créer des mécaniques de précision adaptées aux circonstances, la mutualisation n’est pas la priorité. C’est pourtant dans cette direction que l’industrie du PC et du smartphone se sont engagées. Au départ il y avait des constructeurs intégrés (IBM, Compaq, Nokia) puis avec la maturité les constructeurs sont devenus des assembleurs de parties modulaires, sans valeur ajoutée si ce n’est le “just in time” incarné par Dell. Seul Apple a résisté avec le Mac et l’IPhone. L‘approche modulaire est idéale quand le produit fait le job, que le coût devient le facteur différenciant : il faut alors chercher les économies d’échelle dans toute la chaîne.
A l’inverse l’approche intégrée est nécessaire quand il y a un écart important entre ce qui est fait et ce qui devrait l’être et qu’il faut jouer sur l’intégration des parties pour résoudre le problème: elle permet en optimisant les relations entre les parties de faire progresser le produit, progression prioritaire par rapport au coût. Nous rentrons dans cette phase pour le traitement des données en périphérie. Il faut optimiser la puissance, l’espace et l’énergie et cela requiert une intégration au cas par cas: une voiture autonome va devoir traiter des opérations simples (calcul matriciel) dans un volume peu contraint sans tirer trop sur la batterie. Un smartphone va demander une intelligence plus générale et va devoir faire un choix sur le type d’IA à traiter de manière à éviter que la puce soit trop volumineuse. Chaque cas devient spécifique et nécessite l’intégration de différents processeurs sur un système sur une puce (SOC). Trois exemples permettent de comprendre l’évolution vers plus d’intégration:
la puce Bionic d’Apple: dans sa dernière version (A13), elle comprend deux cœurs CPU haute performance, 4 cœurs CPU basse consommation, le tout sous architecture ARM, 2 GPU capables de traiter les images, enfin un accélérateur IA (neural engine). Le SOC d’Apple fabriqué en 7 nm comprend 8,5 milliards de transistors. Il est intéressant de voir comment Apple a spécialisé ses processeurs pour les optimiser à l’usage. Les deux cœurs CPU (dénommés A13 ligthning) sont optimisés pour la performance quand l’IPhone en a besoin. On peut constater dans le graphique ci-joint la supériorité de cette puce par rapport aux CPU de smartphones comme de PC !

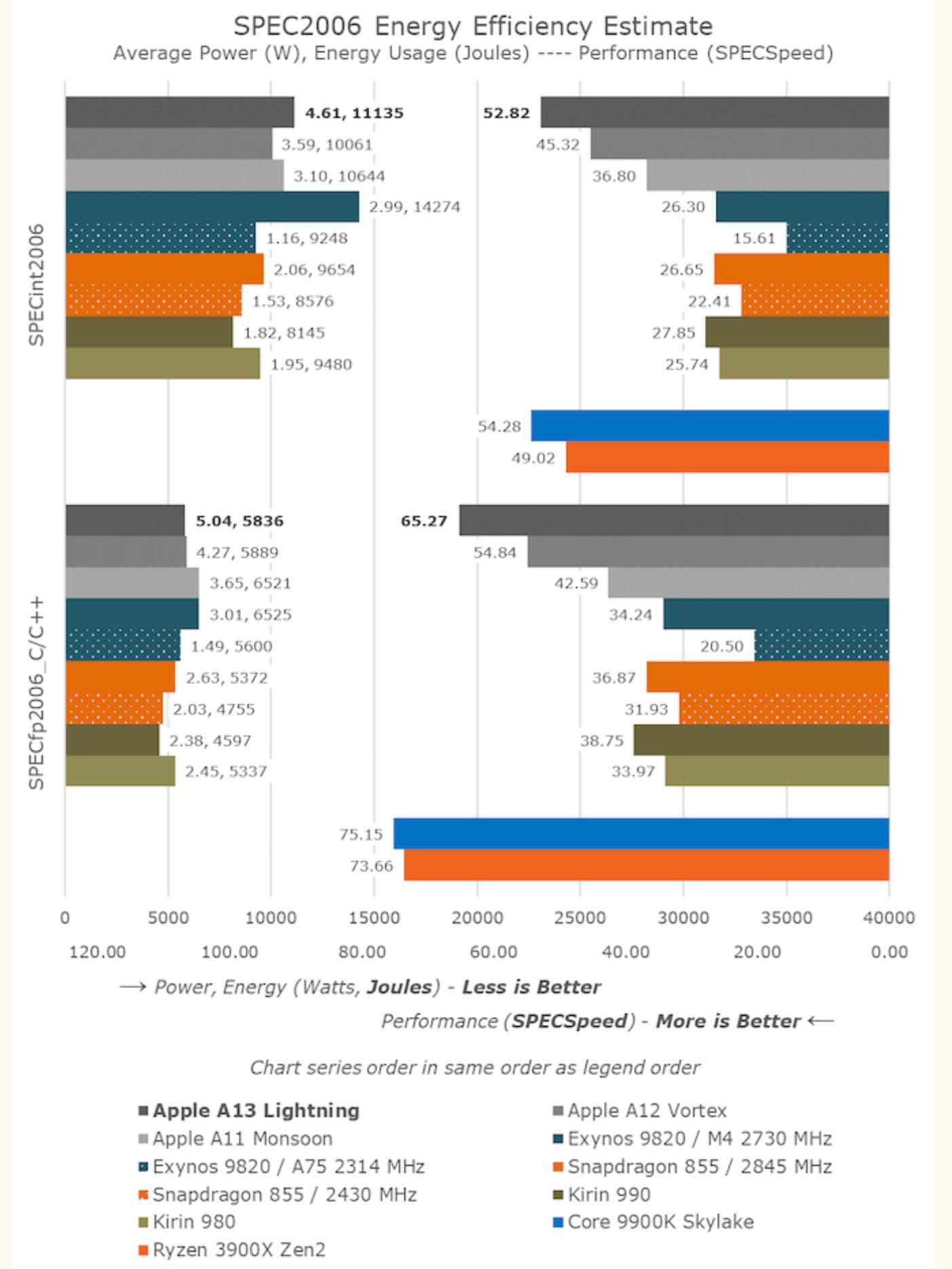
Il faut du très haut de gamme Intel pour rivaliser en puissance (Core 9900 K Skylake). Le SOC peut utiliser les quatre cœurs CPU basse consommation pour les taches ne nécessitant peu de puissance. Les cœurs GPU sont utilisés pour ce qui est nativement leur vocation: le graphisme. Enfin la puce IA est optimisée pour la photo. Tout dans ce SoC est optimisé pour correspondre au plus près à ce qu’Apple attend de l’IPhone, sans gaspillage: une caméra intelligente. Les limitations de la puce, notamment en IA façonnent les caractéristiques de l’appareil centré sur la caméra. On n’a pas encore trouvé la puce IA à tout faire. C’est la beauté de l’intégration selon Apple: tout s’imbrique parfaitement.
La puce Tesla: jusqu’en 2017, Tesla utilisait une puce Nvidia sur son SOC de conduite autonome. Malgré toutes les qualités des GPU Nvidia pour calculer en parallèle, Elon Musk a pris le parti de l’intégration. De Forbes (15 août 2018):
"Je suis un grand fan de Nvidia, ils font des choses formidables", a déclaré M. Musk avant d'ajouter que l'utilisation d'une puce graphique (GPU) n'est pas aussi rapide et rentable qu'une puce personnalisée (ASIC) que Tesla a conçue et teste actuellement sur le terrain.
"Mais en utilisant un GPU, fondamentalement, c'est un mode d'émulation, et puis vous êtes aussi étouffé dans le bus. Ainsi, le transfert entre le GPU et le CPU finit par être une des contraintes du système".
Selon M. Musk, la plateforme de calcul Nvidia Drive PX2 - avec un GPU Pascal et 2 processeurs ou CPU Parker - actuellement utilisée dans l'ordinateur autonome personnalisé de TeslaAutopilot Hardware 2.5 peut traiter 200 images par seconde, contre "plus de 2 000 images par seconde" avec une redondance complète et un basculement avec l'ordinateur conçu par Tesla…Une puce d'IA personnalisée est un ordre de grandeur plus performant et moins gourmand en énergie qu'un système basé sur un GPU pour faire fonctionner des réseaux neuronaux complexes qui sont au cœur d'un système d'apprentissage par machine.
Pour Tesla les contraintes sont de pouvoir analyser précisément extrêmement rapidement une situation sans tirer sur la batterie déjà très sollicitée par la conduite. Les calculs liés à la conduite autonome sont simples (calcul matriciel de base)., mais nécessitent un accès à l’intelligence CPU et à sa mémoire immédiate. La puce Nvidia a été conçue pour des calculs plus complexes, inutiles ici, déploie donc trop d’énergie et de plus cette énergie est en partie perdue du fait d’une connexion difficile avec les CPU (intelligence centrale) et la mémoire. L’intégration permet à Tesla d’adapter parfaitement le SOC de conduite autonome à ses besoins et d’offrir comme Apple une prestation supérieure à la concurrence. Le Soc est gravé en 14 nm, car il n’y a pas de contrainte de taille de la puce dans la voiture; cela permet d’avoir un système meilleur marché.
Signe des temps: même Intel lors de son Architecture Day 2020 tenu le 13 août a révélé sa stratégie sur les PC et ce n’est plus la fabrication de puces monolithiques traditionnelles:
Intel présente des processeurs "client 2.0" conçus sur mesure avec des éléments de base "mixtes".
Alors qu'un grand nombre des nouvelles annonces d'Intel portaient sur des produits à venir d'ici un an ou deux, l'entreprise a également évoqué un changement à plus long terme dans la façon dont elle conçoit les puces de prochaine génération pour les ordinateurs de bureau et les ordinateurs portables à l'avenir.
La société appelle cette nouvelle approche de la conception des processeurs clients "Client 2.0", et elle se concentrera sur la création de processeurs "spécialement conçus" pour différents types d'utilisateurs, comme les joueurs, les créateurs de contenu et les utilisateurs commerciaux. Cette approche sera rendue possible par le mélange et l'association de différentes fonctions et IP en silicium comme éléments de base - pour des éléments tels que le graphisme, le calcul et les E/S - afin de les optimiser pour différentes expériences, ce qui constitue un changement majeur par rapport à l'approche traditionnelle des puces monolithiques d'Intel.
Brijesh Tripathi, vice-président et directeur de la technologie du Client Computing Group d'Intel, a déclaré que le Client 2.0 permettra un temps de développement beaucoup plus rapide que celui des puces monolithiques et multi-matrices, ce qui est rendu possible en partie par le fait que les blocs de construction IP individuels peuvent être réutilisés pour différents produits à un rythme beaucoup plus rapide que sa méthodologie de conception multi-matrices.
"Dans l'ensemble, le Client 2.0 consiste à livrer des produits gagnants à une cadence annuelle", a-t-il déclaré.
M. Tripathi a déclaré que la société prévoit de communiquer plus de détails sur ses projets Client 2.0 à l'avenir.
"Nous y travaillons depuis un certain temps déjà", a-t-il déclaré. "Dans un monde où les clients exigent des expériences extrêmement riches pour chaque cas d'utilisation, nous avons changé la façon dont nous pensons à nos outils de construction et à notre méthodologie. Notre objectif est passé de la construction de SoC monolithiques à usage général à la construction d'appareils évolutifs, conçus spécialement pour offrir une expérience riche aux utilisateurs".
L’industrie des puces pourrait donc prendre deux directions, fonction des données traitées dans le cloud et en périphérie. L’approche du cloud est modulaire: il faut avant tout plus de puissance compatible pour faciliter la tâche des développeurs, donc aligner les puces aux architectures standards (CPU ARM et x86, GPU Nvdia, etc.). C’est l’approche lego développée dans mon article Conteneurs, legos et web 3.0. Toute l’industrie sera favorisée, donc l’ETF SOXX qui va représenter une part plus importante des indices. L’ajustement des capacités à la demande se fera par la quantité de puces déployées, en fonction d’un compromis entre puissance et prix. En périphérie, on ne pourra répondre à la demande aussi facilement, par le nombre. Chaque cas est un mix complexe de contrainte d’espace, de consommation énergétique, de puissance…et de prix. Pourquoi laisser des marges confortables à Intel ou Nvidia qui ne font pas bien le job ? L’intégration permettra de rapprocher l’offre et la demande et de faire la différence. En périphérie, il ne faut pas chercher le nouveau standard des semi-conducteurs mais plutôt le produit fini dont l’intégration des pièces sera la plus parfaite.
Bonne fin de semaine,
Hervé