
Bulle…vous avez dit bulle…
Comme c’est étrange…
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.

Arvind Krishna, PDG d’IBM, interview pour Decoder, le 1er décembre 2025:
Il faut environ 80 milliards de dollars pour équiper entièrement un data center d’un gigawatt. Voilà, ça, c’est le chiffre d’aujourd’hui.
Donc, si vous vous engagez sur 20 à 30 gigawatts – pour une seule entreprise – cela représente 1 500 milliards de dollars de CapEx. Et, comme on vient de le dire, vous êtes obligé de tout utiliser sur cinq ans, parce qu’à ce moment-là vous devez tout jeter et tout remplacer, n’est-ce pas ?
Ensuite, si je regarde le total, ces choses-là, l’ensemble des engagements dans le monde, dans ce domaine mouvant de l’AGI , semblent être de l’ordre de 100 gigawatts, au moins d’après les annonces.
Cela fait 8 000 milliards de dollars de CapEx. Pour moi, il n’y a absolument aucun moyen d’obtenir un retour sur un tel montant, parce que 8 trillions de CapEx signifient qu’il vous faut à peu près 800 milliards de dollars de profit rien que pour payer les intérêts.
Ces propos visent à discréditer la stratégie consistant à investir massivement dans les centres de données pour atteindre l’AGI, l’intelligence artificielle générale. Pour Arvind Krishna ces investissements ne seront jamais rentabilisés. Il dénonce ainsi la mauvaise allocation de capital des « hyperscalers 1» pour mieux mettre en avant sa stratégie beaucoup plus raisonnable. Pourquoi investir maintenant dans des infrastructures qui seront largement obsolètes dans cinq ans alors qu’on peut se concentrer sur des applications d’IA adaptées aux multiples besoins des entreprises quitte à reposer sur des plus petits modèles . Arvind Krishna prêche pour sa paroisse, paroisse obsédée par le cash-flow immédiat et qui en conséquence investit peu: les dépenses d’investissement d’IBM s’élèveront à un peu plus de $1 milliard cette année ($125 milliards pour Amazon) ! Mieux vaut prétendre avec tous ceux qui n’ont pas investi que les autres sont irrationnels …
Par un tour de passe passe intellectuel, Arvind Krishna élude la réelle problématique, en appuyant sur le thème à la mode: la bulle de l’IA générale. Le problème en fait n’est pas trop d’investissement mais pas assez.
Calcul sur un coin de table
Avant de se prononcer sur la rentabilité de ces investissements , il convient de vérifier si les chiffres donnés par Arvind Krishna sont bien réalistes.
Coût du centre de données
Tout d’abord le coût d’un centre de données est manifestement exagéré. Prenons l’exemple du supercalculateur Colossus de xAI qu’on peut qualifier de moderne. Ce centre de données a une capacité aujourd’hui de 0,15 GW grâce à ses 100 000 GPU H100 de Nvidia (coût approximatif de $2,5 milliards). Le coût des GPU représentant 50% à 60% du coût matériel , on peut estimer le reste du coût (serveurs et connectique) à $2 milliards. Enfin l’infrastructure (bâtiment et refroidissement) coûtent environ $1 milliard- vieille usine Electrolux reconditionnée- au total, le coût est de l’ordre maximum de $6 milliards pour 0,15 GW, donc $40 milliards du GW. L’équation ne change pas radicalement avec la génération suivante de puces, les Blackwell 200. Le coût du centre de données est 20% à 25% plus cher notamment parce qu’il exige un refroidissement liquide et non plus simplement de gros ventilateurs. La différence est que le centre de données est beaucoup plus puissants: 3 à 5 fois plus de token produits par seconde.
Conclusion: les chiffres d’Arvind Krishna sont à diviser par 2, dans le cas des puces les plus chères (Nvidia). Un centre de données composé de TPU Google coûtera encore bien moins cher (environ la moitié).
Amortissement du centre de données
Arvind Krishna pointe l’irrationalité des hyperscalers en soulignant que leurs investissements seront à mettre à la poubelle dans cinq ans car les puces seront alors 100 fois plus puissantes. Les H100 d’aujourd’hui seront alors invendables. C’est également une exagération. Les puces d’entraînement, les plus avancées, ont une seconde vie, voire une troisième: les deux premières années, elles servent à l’entraînement des modèles de frontière; les trois années suivantes, elles servent à ajuster les modèles pour les entreprises (fine tuning), enfin après cinq ans elles sont utilisées à fond pour l’inférence (80% de la charge de travail d’ici peu). L’inférence (interrogation des modèles) est plus souple à gérer du point de vue énergétique. En effet pour l’inférence:
On peut compresser le modèle et traiter ainsi des fichiers plus légers.
On peut faire appel à une puce dans n’importe endroit (choix de l’endroit où l’électricité est la moins chère à l’instant t)
On peut regrouper les questions avec celles de 100 autres utilisateurs pour faire baisser les coûts.
On peut confier la charge à des puces inoccupées ce qui évite de sur-solliciter les puces.
Certes une B300 sera plus productive à l’inférence qu’une H100. Mais elle sera également beaucoup plus chère à l’achat. L’hyperscaler utilisera sa vieille H100 tant que :
coût de l’électricité gaspillée par la H100 < coût d’achat d’une nouvelle B300 amortie sur trois ans.
Pour l’entraînement qui nécessite une mécanique de précision inouïe avec des puces en batteries produisant au même moment, l’énergie gaspillée sera vite énorme le calcul penchant pour la B300; concernant l’inférence finir la H100 a du sens économiquement, au moins au coût actuel de l’électricité. Satya Nadella, PDG de Microsoft a insisté récemment sur la fongibilité des puces au sein des centres de données Azure:
Cela remonte un peu à la question de fond : de quoi s’agit-il dans le business hyperscale ? Une des décisions clés que nous avons prises est que, si nous voulions développer Azure pour qu’il soit excellent à toutes les étapes de l’IA — de l’entraînement à la formation intermédiaire, en passant par la génération de données et l’inférence —, nous avions simplement besoin de la fungibilité de la flotte. C’est ce qui nous a essentiellement empêchés de construire une grande capacité autour d’un ensemble particulier de générations.
Parce que l’autre chose que vous devez réaliser, c’est que, jusqu’à présent, nous avons multiplié par 10 tous les 18 mois notre capacité d’entraînement suffisante pour les divers modèles OpenAI, et nous avons compris que la clé était de rester sur cette trajectoire. Mais la chose plus importante encore est d’avoir un équilibre : ne pas se contenter d’entraîner, mais être capable de servir ces modèles partout dans le monde. Parce qu’au bout du compte, c’est le rythme de monétisation qui nous permettra de continuer à financer tout cela. Et l’infrastructure allait devoir nous permettre de supporter de multiples modèles.
Satya Nadella critique indirectement les « neo-clouds », comme Nebius ou CoreWeave qui misent tout sur les GPU les plus avancés mais gaspillent du capital. Ils ont peut être des coûts d’électricité moindre mais à quel coût global ? Satya Nadella avance un autre argument plus profond en faveur de la fongibilité: la variété des services rendus.
Le risque de non fongibilité
La denrée rare, aujourd’hui, plus que l’électricité est l’attention. Cela explique pourquoi OpenAI est prêt à brûler environ $9 milliards de cash cette année pour augmenter son nombre d’utilisateurs hebdomadaires (environ 900 millions) et surtout le temps passé sur ChatGPT, ce pourquoi il n’est pas pressé à placer de la publicité sur l’offre gratuite (risque de dégrader l’expérience). Cela explique aussi l’avantage concurrentiel de Google ou Meta qui sont maîtres dans l’art de retenir l’attention, multipliant les occasions de revenir sur leurs plateformes aux milliards d’utilisateurs de celles-ci. La clé est d’avoir différents services à proposer pour faire revenir l’utilisateur à la moindre occasion. Certains nécessitent l’utilisation de modèles de frontière nécessitant un entraînement massif, d’autres peuvent s’accommoder de modèles plus modestes et d’une partie logiciel plus significative. Le fonctionnement d’Excel par exemple ne demande pas d’utiliser des B300. L’hyperscaler adopte la stratégie du lissage remplaçant 10% à 20% de ses puces tous les ans, pour disposer en permanence des puces les plus évoluées pour les charges les plus intenses. Tout remplacer comme le suggère Arvind Krishna serait du gaspillage au départ et l’assurance de ne plus disposer de puces de dernière génération l’année suivante ! Dès lors, le service globalement se dégraderait avec un risque important sur l’engagement des utilisateurs. Les hyperscalers ne peuvent commettre une telle erreur.
Le PDG d’IBM exagère donc l’investissement nécessaire pour un centre de donnée et minimise la durée de son amortissement. Qu’en est-il du chiffre de 100GW de capacité annoncés par les grands acteurs ?
100 GW: le mur de la réalité
Il ne faut pas confondre les désirs de construction et la réalité matérielle. Aligner 100 GW de capacité au cours des cinq prochaines années est impossible. Krishna pour obtenir son chiffre a additionné les déclarations d’intention:
mega projets sur site unique =15 GW (Stargate d’OpenAI/Microsoft, campus Talen Energy d’Amazon, campus d’Oracle, centre de donnée de Memphis pour xAI);
ajout organique des hyperscalers=40 GW (2GWx 4 acteurs x 5 ans);
colocataires comme Equinix ou Digital Realty: 25 GW;
pays souverains (Chine/Moyen-Orient) et néo-clouds: 20 GW
15 GW+40 GW+25 GW+20 GW=100 GW
Dans les faits, la capacité du réseau électrique mondial sera bien insuffisante pour permettre une telle construction de centres de données sur les cinq prochaines années.
Aux Etat-Unis, il y a un double goulet d’étranglement: les lignes haute tension sont saturées et il y a pénurie de transformateurs (haute tension /moyenne tension). Afin gagner du temps, on change les fils pour leur donner plus de capacité et on raccorde les centres de données à des lignes à moyenne tension (Virginie) ; on concentre l’ajout de génération (Texas, plus libéral, terrain de jeu d’xAI, Google et Meta); on recycle des usines disposant de vieux transformateurs qu’on rénove (Rust Belt) ; on profite de l’ensoleillement massif pour ajouter des panneaux solaires (Arizona, Nevada). Au total les Etats-Unis pourraient ajouter 20GW au réseau au maximum. Une solution de contournement serait de connecter directement des centrales aux centres de données. C’est impossible pour les centrales déjà en activité (avis du régulateur sur un projet Amazon) mais possible quand il n’y a pas concurrence avec le réseau public. Le projet de Microsoft concernant le réveil de la centrale de Three Mile Island cependant ajoute moins d’1 GW à la capacité électrique des Etats-Unis. Les réacteurs nucléaires modulaires (SMR) sont une solution séduisante mais malheureusement encore sur le papier, le spectre des accidents potentiels étant trop fort.
L’Europe est d’avantage concentrée sur le raccordement d’éoliennes et de panneaux solaires à son réseau qu’au branchement des centres de données. Ceux-ci requièrent en effet une énergie de base 24/24 pour l’entraînement, typiquement du nucléaire qui n’est pas la priorité. Son énergie et chère et sa bureaucratie paralysante. Aussi il est peu probable que l’Europe constitue un terrain de chasse intéressant pour la construction de centres de données, hormis pour l’inférence de luxe locale. En tout cas, il ne faut pas compter pouvoir entraîner des modèles avancés. On peut estimer à 5 GW l’ajout de capacité sur cinq ans.
En dehors de l’Occident, le pourvoyeur important sera la Chine qui pourrait ajouter 12 GW grâce à son charbon qui sert de charge de base. Cette capacité pas forcément très efficiente (restriction des Etats-Unis sur l’exportation de puces) sera réservée à l’entraînement et l’inférence de ses propres modèles. Enfin il faut compter avec le Moyen-Orient qui regorge d’énergie bon marché et à peu de contraintes écologiques. Il pourrait construire 2 GW de centres de données mais subit des restrictions sur l’achat de GPU. En Inde le réseau reste fragile et peu sûr.
Au total, un plafond de l’ordre de 40GW pour les nouveaux centres de données paraît réaliste, soit 40% du chiffre avancé par Arvind Krishna.
Si on reprend l’ensemble de ces éléments, les investissements pour les cinq prochaines années seraient: $40 milliards (coût d’un centre de données d’1 GW) x 40 GW, soit $ 1 600 milliard, loin des chiffres du PDG d’IBM.
Toujours plus de token
La demande de token2 est en hausse exponentielle en entrée et en sortie/réponse (les sorties représentant environ 70% du total). Quand on commence à utiliser un modèle, il n’y a pas de retour en arrière: l’intelligence est addictive. Prenons l’exemple de Google. En avril 2025, Sundar Pichai l’illustrait lors d’une présentation:
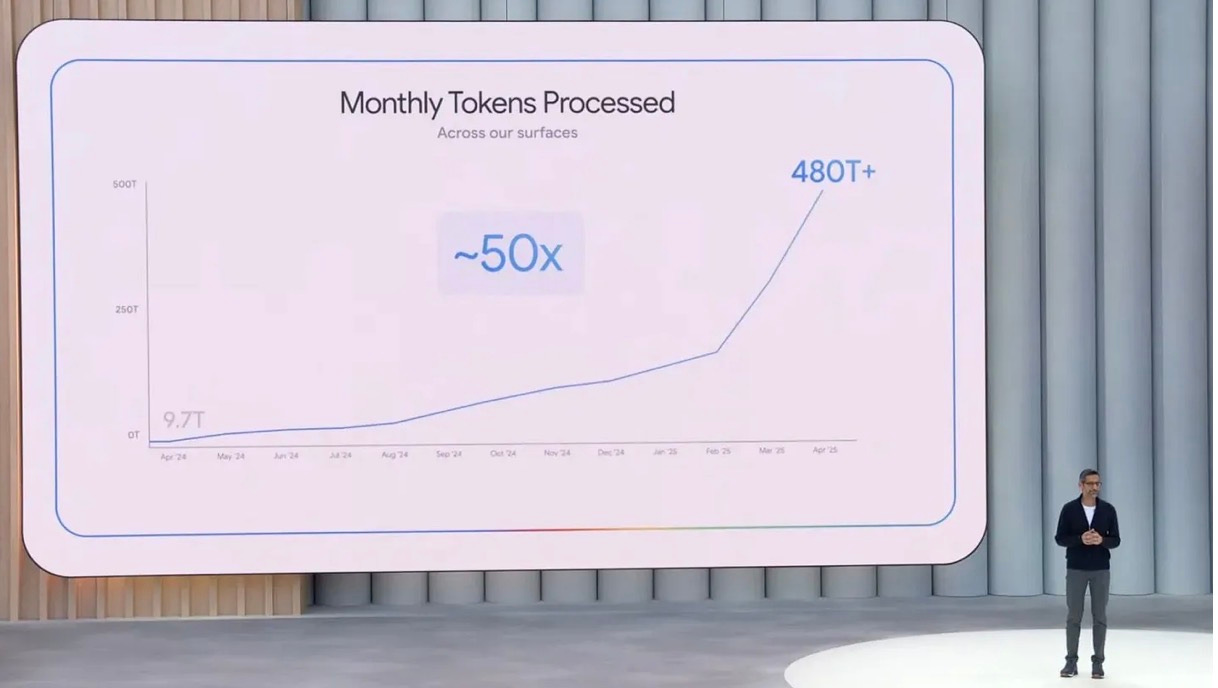
Depuis Google a actualisé les chiffres:
-1 quadrillion en juillet.
-1,3 quadrillion en octobre.
Ceci avant la sortie de Gemini 3. L’accélération de la hausse, perceptible à partir de février 2025, est due au post-training et à l’introduction de modèles qui pensent (c’est à dire reviennent sur ce qu’ils ont produit pour le rectifier). DeepSeek a commencé et depuis tous les modèles se sont mis à « penser ». La pensée elle-même génère 10 000 token pour vous en produire 100. Une autre accélération va se produire avec l’adoption des agents, en particulier dans les entreprises. En effet, les agents composent les token pour réaliser une tâche. Le deal pour une entreprise est particulièrement intéressant: un abonnement ChatGPT coûte €23 par mois, un salarié au SMIC plus de € 1900, et un cadre… ? Les gains de productivité potentiels sont colossaux. Plus il y aura de token, plus le modèle deviendra intelligent (vérifiant ses réponses et corrigeant ses erreurs) et plus il sera susceptible de remplacer des flux de travail humains. En vendant leurs modèles à €20 par moi, les grands modèles de langage créent un surplus très important.
Ce qui permet cette accélération est la baisse du coût des token, selon la loi de Devon: quand le prix d’un bien baisse, sa consommation augmente. Voici cette évolution depuis un an pour Gemini le producteur à bas coûts:
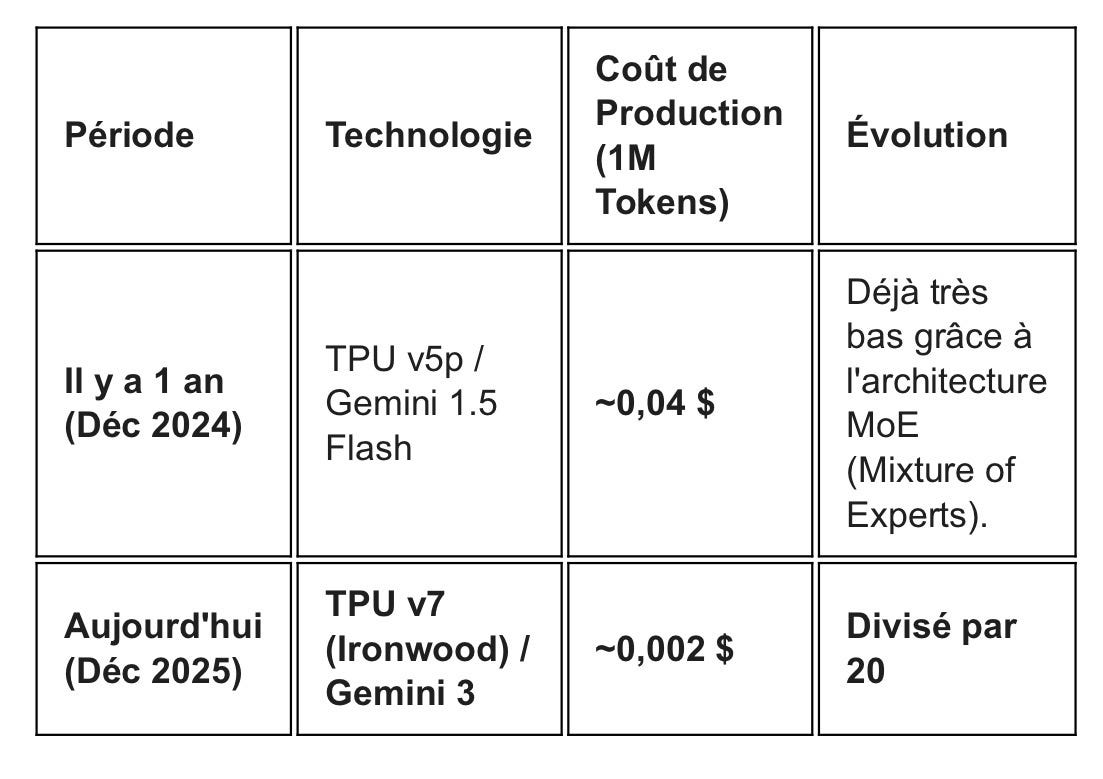
Et pour ChatGPT, le producteur aux coûts les plus élevés:
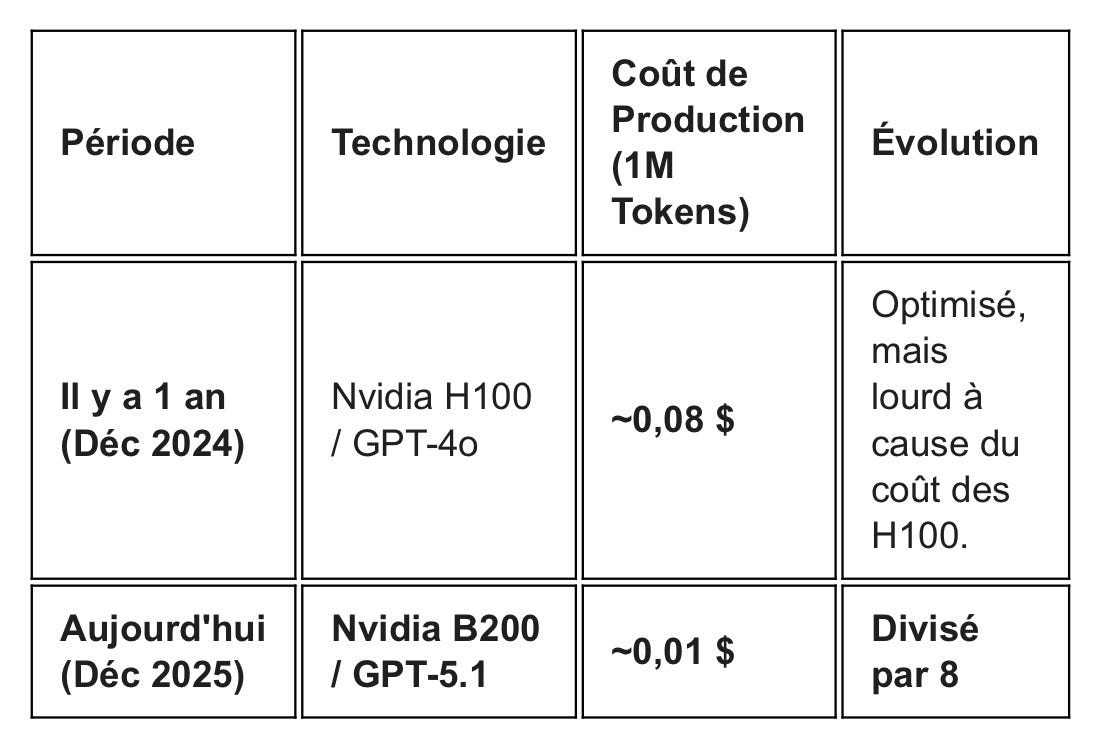
Une meilleure productivité des puces et une structuration plus économe des modèles permettent cette baisse des coûts. L’entraînement de Gemini 3 à partir des TPU v7 montre que l’effet d’échelle est toujours aussi important pour l’entraînement. Les modèles à base de Blackwell 300 qui sortiront en 2026 confirmeront la tendance et séduiront par leur niveau d’intelligence…
En bref des modèles plus intelligents et moins chers donc qui seront de plus en plus utilisés.
Il faut donc considérer l’effet des 1 600 milliards d’investissements sur la productivité: si cette dernière s’améliore de 1% l’an sur un PNB mondial de $120 000 milliards, le magot à se partager sur 5 ans s’élèvera à $6 000 millards, soit presque 4 fois l’investissement. Cette amélioration est d’autant plus plausible si on considère l’amélioration de productivité déjà réalisée chez les hyperscalers, les premiers sur le pont.
Les cash-flows
On comprend pourquoi les hyperscalers investissent massivement, surtout qu’ils en ont les moyens. Les cash-flows opérationnels combinés de Google, Microsoft, Meta et Amazon s’élèveront à plus de $ 600 milliards en 2025. En moins de trois ans, les investissements maximum autorisés par le réseau énergétique seront réalisés et ce sans recourir à la dette. Où est la bulle ? Certes un certain nombre d’acteurs marginaux (type néoclouds) pourront tomber car ne bénéficiant pas assez des mécanismes d’attention, mais le cœur reste sain. Il bénéficie à plein des effets d’échelle, des effets réseaux et des cash-flows.
Dégager les points bloquant
La contrainte énergétique s’imposant, l’enjeu va être de maximiser la performance par watt, tant en entraînement qu’en inférence.
Les accélérateurs
Dans le coût de fonctionnement d’un accélérateur type GPU, il y a principalement deux postes: l’amortissement et l’électricité. Plus il va y avoir de pression sur le coût de l’électricité, plus ce poste prendra de l’importance par rapport à l’amortissement. Autrement dit, on va rechercher la performance brute de la puce prioritairement (nombre de TFLOPS/100W pour l’entraînement, nombre de token par W pour l’inférence), quitte à payer plus cher celle-ci. Le tableau suivant montre l’amélioration de la performance par watt en fonction des générations:
Entraînement
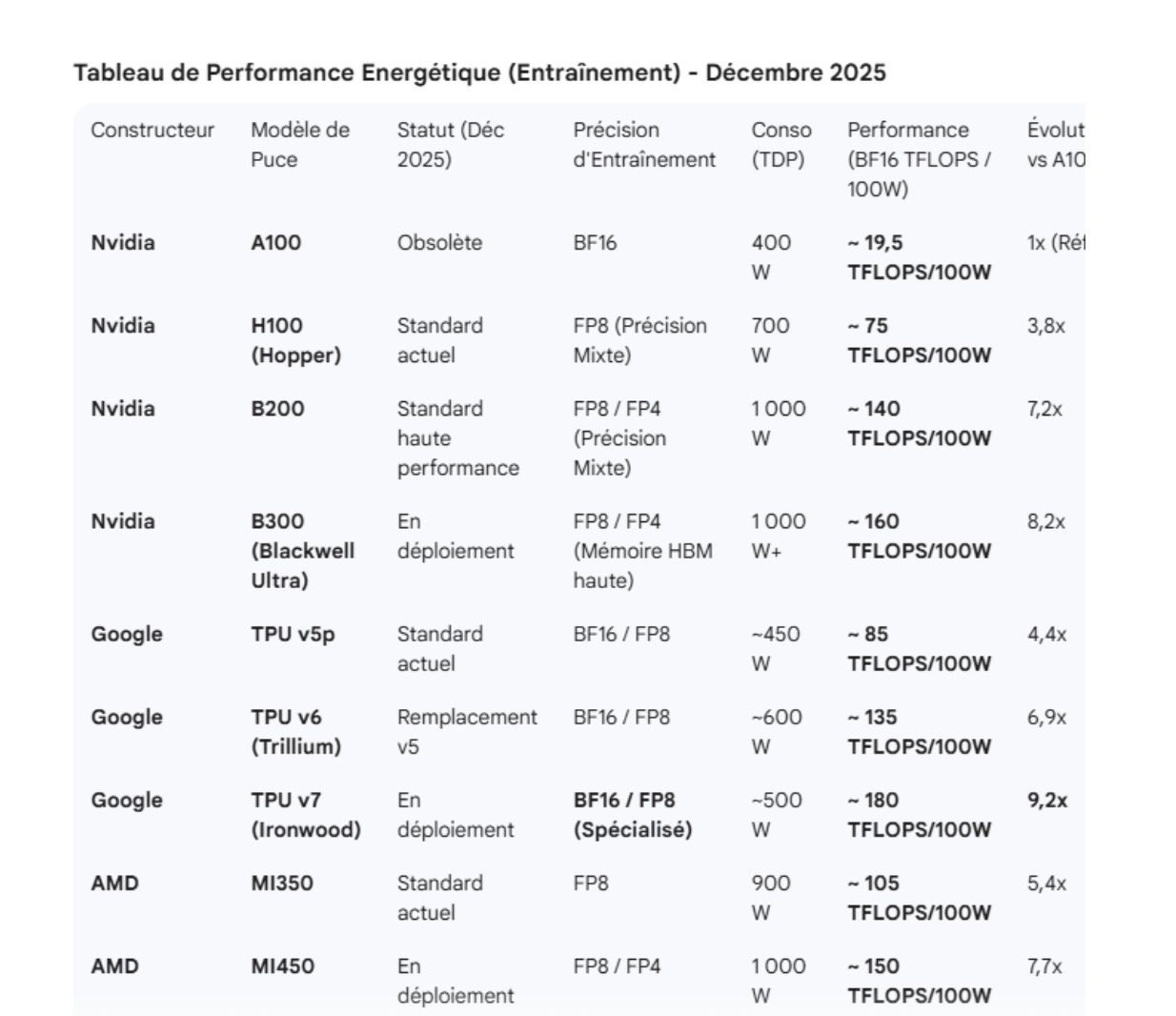
Inférence :
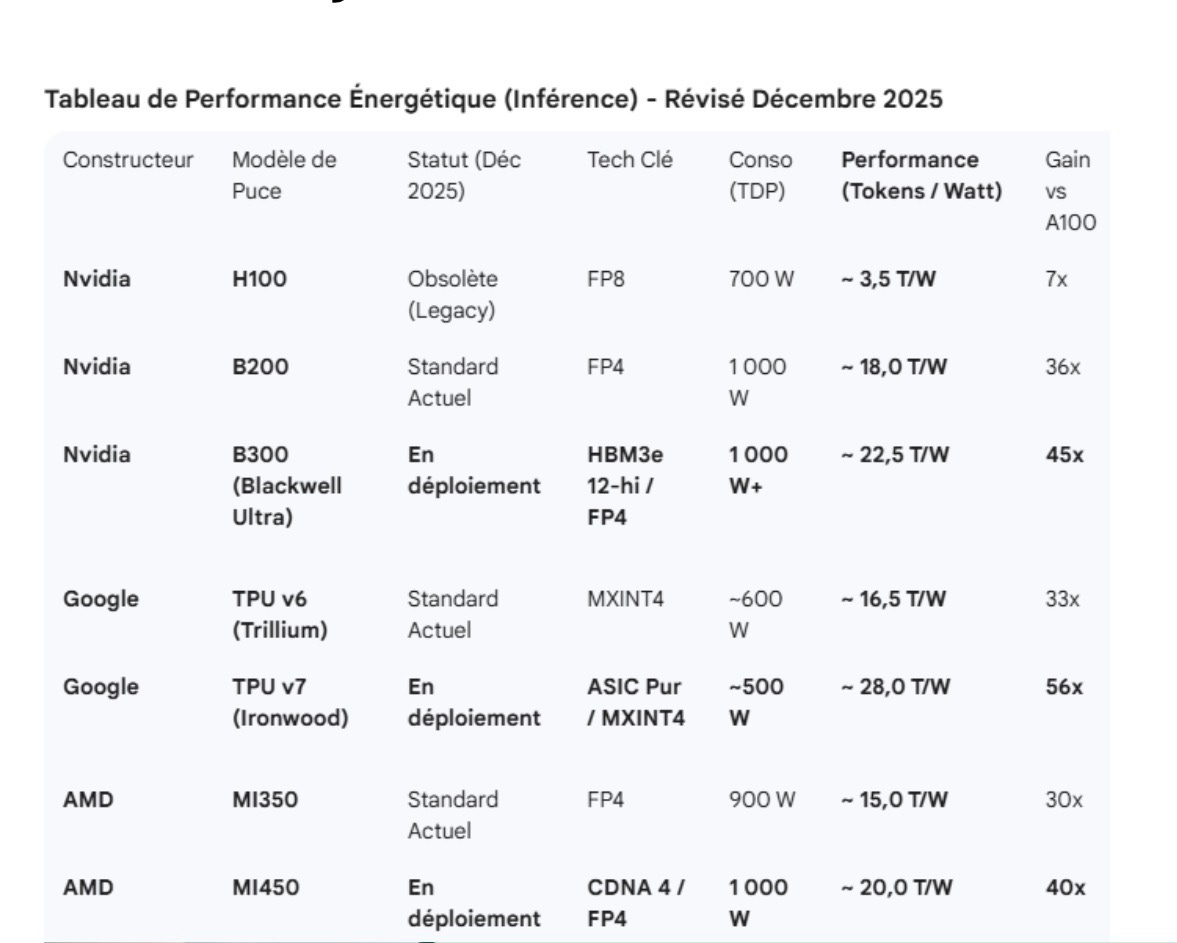
L’écart de performance est impressionnant à chaque génération. Les fabricants vont se battre pour gagner le prix du maximum de performance/watt et ainsi vendre leurs puces à des prix premium. Cette contrainte électrique explique pourquoi Google s’est décidé à vendre ses TPU à l’extérieur car ils deviennent un élément très prisé dans la chaîne de l’IA.
Autour des accélérateurs
Les accélérateurs ne travaillent pas seuls (en particulier pour l’entraînement) et leur performance dépend grandement de leur environnement. Dans la phase d’entraînement, il faut surtout éviter les défaillances. La moindre erreur oblige à tout recommencer, ce qui coûte très cher en énergie. De fait la progression de la performance par watt est bien inférieure pour l’entraînement que pour l’inférence (x9 au lieu de x66):
1/ le calcul doit être extrêmement précis ce qui entraîne facilement des surchauffes et donc défaillance (la puce s’arrête pour éviter de fondre).
2/ les puces doivent communiquer entre elles à la vitesse de la lumière (occasion de défaillance)
3/ les données transites constamment entre puces et mémoires (occasion de défaillance)
4/ le chef d’orchestre (CPU) doit être puissant et efficient, ne pouvant se permettre le moindre retard sur l’exécution.
Il y a donc autour de la puce des points bloquants potentiels qu’il faut lever à chaque génération: refroidissement (20% à 40% de l’énergie totale dépensée), transport, mémoire et intelligence générale. Ces points bloquants ralentissent l’offre et donc la formation d’une bulle.
Hardware à la périphérie
Si les centres de données tournent à 100 % de capacité, de plus en plus de requêtes seront traitées en local, sur l’appareil ou sur des petits serveurs à proximité des utilisateurs. C’est le sens de la prédiction de Musk par laquelle j’ai commencé mon article We shall prevail:
C’est une prédiction facile de la direction que prennent les choses : les appareils ne seront plus que des terminaux en bout de chaîne pour faire tourner l’inférence d’IA, parce que les limites de bande passante empêchent de tout faire côté serveurs.
C’est la stratégie d’Apple sur l’IA: 1/ fabriquer des terminaux sur lesquels l’inférence locale est quasi parfaite et gratuite ! 2/ Décharger les taches plus complexes sur des serveurs proches des utilisateurs. Apple a créé une app (Locally Ai) qui vise à constituer une plateforme de petits modèles tournant sur l’iPhone.
Il y a donc un marché très important pour l’inférence locale sur des modèles plus modestes que les modèles de frontières mais qui à terme pourront faire 90 % du job. C’est là où IBM essaiera de faire la différence. Il ne sera pas seul…
La fonderie
TSMC est la seule fonderie capable de produire des noeuds avancés (2 nm) de GPU, sans risque d’exécution. La sécurité est un élément fondamental car il y a des quotas de production, un raté pouvant entraîner un retard considérable par rapport aux autres. Pour le 2 nm (prochaine génération), les quota se répartissent entre:
Apple 38%
Nvidia 22%
AMD 18%
Qualcomm 22%
Google 6%
Autres 4%
Le carnet de commande est très tendu, ce qui pourrait inciter les concepteurs à « s’assurer » après de la seule fonderie avancée des Etat-Unis, celle d’Intel. Apple pourrait se lancer le premier pour ses puces M les moins haut de gamme en 2027. Intel fabrique surtout pour lui-même et jusqu’à peu se souciait peu du rendement de ses puces, étant son propre client. Cela est en train de changer mais la culture est tenace et les concepteurs se méfient.
Là aussi, le blocage au niveau de la fabrication s’ajoute au blocage énergétique et restreint l’offre. Forte demande et faible offre ne sont pas les terreaux d’une bulle…
Nouvelle frontière
Installer un centre de données dans l’Espace présente des avantages:
les rayons du soleils sont plus puissants en basse orbite que sur terre et on peut les capter plus longtemps. La production d’électricité sur 24 h est multipliée entre 4 et 8 fois selon l’orbite retenu; les batteries, principal coût pour l’énergie solaire, sont réduites au minimum.
Comme la contrainte de terrain n’existe pas et que les liaisons dans le vide sont aisées, il est possible de construire des centres de donnés géants sans commune mesure avec ceux existant sur terre (plusieurs TW à terme au lieu de GW).
En revanche refroidir les puces est un cauchemar. En effet le vide est un parfait isolant qui ne dissipe pas la chaleur. La bonne nouvelle est qu’on peut trouver des solutions car un matériau non exposé au radiations se rapproche du zéro absolu. De plus l’énergie en orbite est bon marché ce qui permet de créer à bas coût des réfrigérateurs.
Les hyperscalers ont leur plan pour créer cette infrastructure informatique en basse orbite et échapper ainsi à la contrainte énergétique terrestre. Chacun essaie de valoriser ses points forts:
Elon Musk veut utiliser les satellites Starlink à la fois pour véhiculer l’Internet et traiter les données. Son idée est de lancer des satellites d’un nouveau type qui font relai internet et sur lesquels sont plaquées des puces haut de gamme pour traiter des données. Les satellites communiqueront entre eux pour échanger les données. La chaleur des puces se dissipera par la face non exposée aux radiations des satellites sur lesquels les puces sont fixées. Les satellites ayant un double usage, les communications entre eux se font par envoi de paquets (comme l’Internet) avec une certaine latence. Ces centres de données sont donc adaptés à l’inférence et pas à l’entraînement. Elon Musk a un atout majeur: SpaceX qui lui permettra de réduire le coût d’installation de ses centres de données. En revanche si les puces grillent, il faut jeter tout le satellite. Elon Musk doit jouer le « low cost ».
Google n’a pas cet avantage « low cost »et dépendra des fusées que SpaceX voudra bien lui réserver. En revanche sa force est le branchement optique entre ses racks et centres de données qui lui permet d’aligner une puissance de feu considérable pour l’entraînement. Il travaille donc au déploiement d’un cluster géant mono-fonction dans l’espace pour l’entraînement. Comme ses serveurs ne serviront pas à transmettre l’Internet, ils n’ont pas besoin d’être proches des lieux de concentration humaine et peuvent chasser l’orbite crépusculaire pour bénéficier des rayons du soleil 24/24. Ainsi Google fait l’économie des batteries. De plus ses satellites regardant toujours le soleil, la face cachée peut dissiper la chaleur.
Amazon a une solution basique mais qui tire parti des économies d’échelle d’AWS. Son centre de données, envoyé par Blue Origin (Bezos), ressemblera à un centre de données terrestre avec les mêmes puces (Trainium) et des systèmes de refroidissement géant. Amazon fera des économies sur le centre de données même si l’énergie lui coûtera plus cher qu’à Elon Musk.
Enfin Microsoft ne va rien envoyer mais a passé un accord avec SpaceX pour constituer la partie logicielle du dispositif: il loue des antennes au sol pour récupérer les données des satellites des autres et les traiter. Son service s’appelle Azure Orbital. Il veut ainsi faire concurrence à Amazon en s’associant avec celui qui a la meilleure constellation de satellites.
L’espoir pour désengorger les centrales terrestres est Elon Musk qui mène son projet au pas de charge et pourrait être le seul à disposer d’une capacité consistante dans les cinq prochaines années comme le montre le tableau suivant:

Et cela ne suffira pas pour atteindre les 100 GW d’Arvind Krishna !
Je vous souhaite un joyeux Noël,
Hervé
Un hyperscaler est un opérateur capable de déployer et d’exploiter à très grande échelle des infrastructures cloud (datacenters massifs, réseau mondial, capacité d’auto-provisioning, services “à la demande”, industrialisation logicielle/ops).
Un token est une unité de texte utilisée par les modèles de langage. Ce n’est pas forcément un mot : c’est plutôt un “morceau” de texte. En français/anglais, 1 token ≈ 3–4 caractères en moyenne. Donc 1 mot ≈ 1 à 2 tokens en moyenne (mais ça varie beaucoup selon la longueur des mots, la ponctuation, etc.).