


Un million de GPUs
Les cimetières sont remplis de sociétés qui n’ont pas compris les règles du jeu.

Larry Ellison, CEO Oracle, le 9 septembre 2024:
Cette course pour construire un réseau neuronal de plus en plus performant se poursuit à l’infini. Et le coût de cet entraînement devient astronomique. Lorsque je parle de construire des centres de données gigawatts ou multi-gigawatts, je veux dire que ces modèles d'IA, ces modèles frontières vont - le prix d'entrée pour un vrai modèle frontière, de quelqu'un qui veut être compétitif dans ce domaine, est d'environ 100 milliards de dollars. Laissez-moi répéter, environ 100 milliards de dollars.
C'est sur les quatre ou cinq prochaines années pour quiconque veut jouer dans ce jeu. C'est beaucoup d'argent. Et ce n'est pas plus facile. Il n'y en aura donc pas beaucoup…
Donc, si votre horizon se situe dans les cinq prochaines années, peut-être même dans les dix prochaines années, je ne m'inquiéterais pas de savoir si nous avons formé tous les modèles dont nous avons besoin et s'il ne nous reste plus qu'à faire de l'inférence. Je pense qu'il s'agit d'une bataille permanente pour la suprématie technique qui sera menée par une poignée d'entreprises et peut-être un État-nation au cours des cinq prochaines années au moins, mais probablement davantage au cours des dix prochaines années. Ce secteur ne cesse donc de prendre de l'ampleur. Il n'y a pas de ralentissement ou de changement à venir.
Permettez-moi de dire quelque chose qui va vous sembler vraiment bizarre. Vous direz probablement qu'il dit tout le temps des choses bizarres. Alors pourquoi annonce-t-il celle-ci ? Soyons vraiment bizarres. Nous sommes en train de concevoir un centre de données au nord du gigawatt, et nous avons trouvé l'emplacement et la source d'énergie.
Un gigawatt peut alimenter un centre de données de 1 000 000 H1001
Jusqu’à peu les centres de données les plus performants contenaient l’équivalent d’environ 20 000 H100, voire 32 000 pour Oracle. Ainsi Llama 3 a été entraîné sur deux super calculateurs de Meta à 24 000 H100 chacun. Grok2, le dernier modèle en date de xAI a été entraîné sur 20 000 H100. GPT-4 lui a été entrainé sur l’équivalent de 8 000 H100.
Elon Musk met la barre plus haut: son dernier centre de données Colossus, qui vient d’être achevé, contient 100 000 H100. Il prévoit d’augmenter sa capacité à l’équivalent de 300 000 H100 d’ici fin 2024. Les 100 000 H100 serviront à entraîner la prochaine génération de modèles (Grok 3 en l’occurrence) avec un coût multiplié par 6, de quelques centaines de millions de dollars ($700 millions environ) à quelques milliards de dollars ($4 milliards environ). Et maintenant Larry Ellison projette un centre de données chiffré en dizaine de milliards de dollars, tandis que Microsoft s’allie à BlackRock pour investir jusqu’à $100 milliards dans son infrastructure d’intelligence artificielle…dans le même esprit, il signe un accord avec Constellation Energy pour utiliser les 800 Mégawatts de la vieille centrale nucléaire de Three Mile Island pendant 20 ans dès 2027. Jusqu’où ira-t-on ?
Pourquoi une telle frénésie ?
L’ampleur de ces projets semble en décalage par rapport à l’efficacité des produits actuels et à leur manque de capacités. Le bot est aujourd’hui l’expression la plus aboutie de l’IA générative. ChatGPT est de loin le produit le plus prisé avec un chiffre d’affaires en rythme annuel de $4 milliards (10 millions d’abonnés ChatGPT plus, 1 million d’abonnés groupes et de nombreux développeurs utilisant l’API2). En dehors de ChatGPT, les résultats visibles ne sont pas pour l’instant à la hauteur du battage médiatique; voir mon article Où sont les produits ?
Pourtant, six sociétés au moins sont lancées dans la course pour créer le sur-homme digital: OpenAI, Microsoft, Google, Meta, Amazon et xAI (Elon Musk). Quelques autres sont décidées à investir massivement en soutien comme Nvidia ou Oracle, persuadées que l’objectif est inéluctable. Ces sociétés considèrent que l’avantage concurrentiel qu’elles ont construit au cours du temps (les applications de productivité pour Microsoft, le moteur de recherche pour Google, les communications pour Meta, le commerce en ligne pour Amazon, la robotique pour Elon Musk) ne suffit plus à les protéger, si une IA générale voit le jour. Le risque à ne pas être le premier ou un des tous premiers est trop grand car le vainqueur prendra toute la place ( se mesurant en $trillions) et ce sera la faillite probable pour les autres. Il n’y a qu’à voir comment une nouvelle génération de modèle généraliste rend obsolète la précédente. Les patrons de ces grands groupes revisitent la pari de Pascal: si le sur-homme digital n’existe pas, ils n’auront au pire perdu que quelque cash-flow à égalité les uns et les autres. En revanche s’il existe et qu’ils ne l’ont pas trouvé, ils seront voués aux flammes de l’enfer boursier. Seul Apple ne semble pas sensible au pari de Pascal, centré d’avantage sur les produits d’IA que sur la performance des modèles, persuadé que son iPhone le protège.
Écoutons Mark Zuckerberg sur sa volonté de construire (en anglais):
Le mythe de l’argent gaspillé
Il ne faut pas croire que les dizaines de milliards de dollars investis par les BigTech dans des montagnes de serveurs ne leur sont pas déjà profitables. En effet, avant de concevoir des produits d’IA pour compte de tiers, ils s’appliquent leur propre cuisine, remplaçant du personnel par des programmes moins chers et plus efficaces. Comme par magie, leur retour sur investissement augmente ces derniers temps, ce qui est peu compatible avec l’idée d’une mauvaise allocation de ressources.
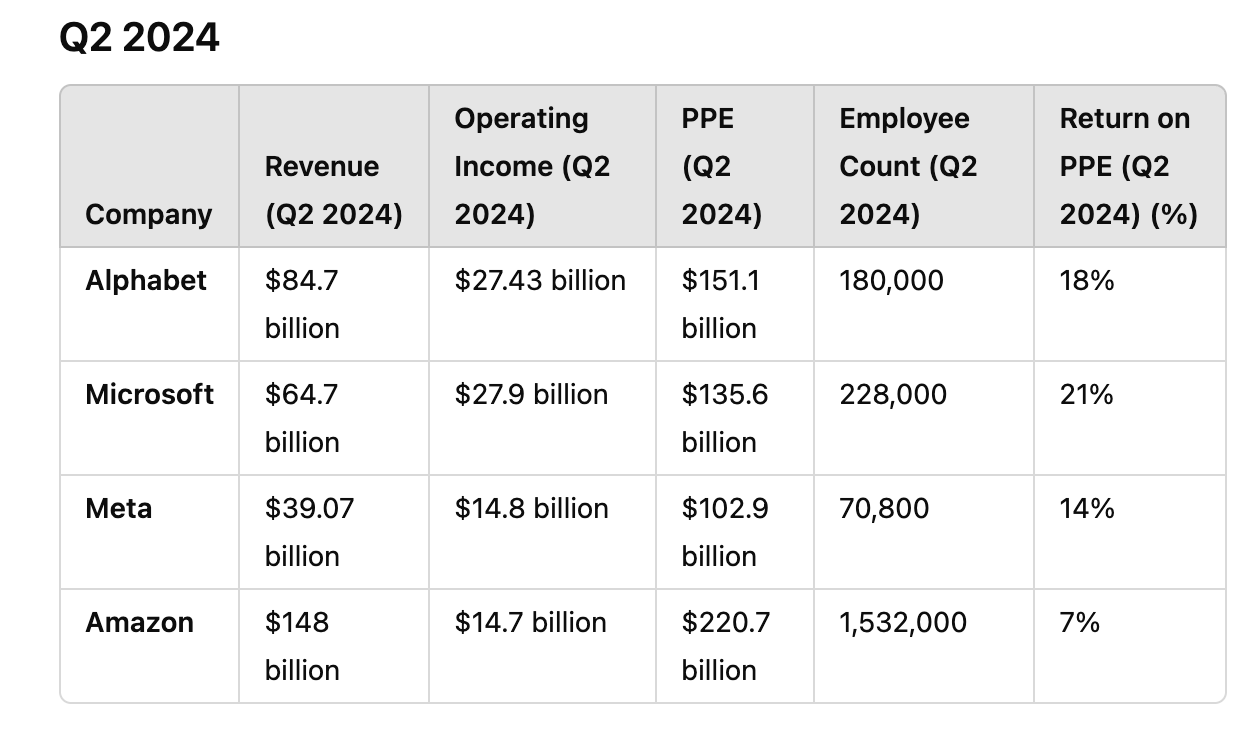

Les chiffres sont éloquents:
un chiffre d’affaires en augmentation en raison de la pertinence des produits. L’intelligence artificielle permet en effet de mieux cibler.
Une réduction relative des coûts, l’IA remplaçant certains flux de travail.
Un bénéfice opérationnel et un retour sur PPE3 en forte hausse.
Microsoft est l’exception, probablement parce qu’il est moins avancé que les autres en IA et doit combler très vite son retard en investissant pour OpenAI.
L’IA aide les BigTech à transformer des frais variables (salaires) en frais fixes (serveurs), abaissant ainsi leur coût marginal et augmentant leur retour sur investissement. L’IA ne prend pas forcément la forme d’un produit de consommation. Elle reste souvent invisible, ce qui n’empêche son efficacité et ce qui encourage ses utilisateurs (les BigTech) à en demander toujours plus. Le pari de Pascal devient alors d’autant plus intéressant, puisque l’on gagne à tous les coups du moment qu’on investit dans les centres de données.
Comment ?
Pour faire progresser une IA, il y a schématiquement trois critères: l’algorithme, les données et la taille du modèle. On peut arguer de l’importance relative de chacun de ces critères. OpenAI a privilégié la taille (GPT-4 dépasse tous les autres modèles en nombre de paramètres), Google est d’avantage axé sur les algorithmes (il a inventé le Transformer) et Meta sur les données (Llama a été entrainé en s’inspirant du modèle Chinchilla). Cependant, il y a un consensus sur le fait que pour faire un bon vers l’intelligence générale, il faut également faire un bon de puissance de calcul. Chaque génération (GPT-2, GPT-3, GPT-4…) entraine une multiplication de la puissance de calcul (par 100 de GPT-2 à GPT-3, par 10 de GPT-3 à GPT-4). La prochaine génération de modèle nécessitera 100 000 équivalent H100, la suivante 300 000 et vite derrière 1 000 000 H100, nécessitant 1 GW de puissance électrique. Par comparaison, la centrale nucléaire de Gravelines dans le nord de la France a une capacité de 5,4 GW et alimente 5 millions de foyers.
La contrainte des coûts
A partir du moment où les protagonistes cités plus haut visent tous le même objectif, celui du sur-homme digital, leur différenciation devient ténue. Car si l’un arrive à créer le sur-homme digital, il y a toutes les chances qu’il soit très vite égalé. Peu ou prou, les modèles à l’intérieur d’une même génération se valent. Dès lors, il est impératif d’être un producteur à bas coûts: les coûts bas permettent de fixer des prix bas, qui permettent d’attirer des utilisateurs. Plus il y a d’utilisateurs, plus les coûts fixes sont amortis sur une plus grande base. Il y a alors une dynamique vertueuse de baisse des coûts et d’agrégation d’utilisateurs.
Comment donc avoir des coûts bas ? Il convient de distinguer deux sortes de coûts: ceux pour entraîner le modèle et ceux pour l’interroger (entraînement et inférence).
Entraînement
L’entraînement d’un modèle se produit au sein d’un centre de données4. C’est donc celui-ci qu’il faut rendre le plus efficace possible. Les GPUs sont une composante du centre de données parmi d’autres: il ne suffit pas de les aligner pour avoir le modèle le plus puissant et économique possible. Il faut optimiser l’ensemble du centre de données, incluant la puissance de calcul (GPUs/CPUs), le stockage et la mémoire (RAM), avec des liaisons entre tous ces éléments, des systèmes de transmission de l’énergie électrique et le système de refroidissement. L’unité de lieu (le centre de données) est importante pour que toutes les parties soient coordonnées simultanément pour chaque étape d’entraînement. La coordination est d’autant plus délicate que le nombre de GPUs est élevé: à un instant t, chaque GPU a en mémoire ce que font les autres. Il suffit d’un GPU qui lâche pour devoir revenir à l’étape t-1 pour l’ensemble (l’étape précédente ou tout l’entraînement a été stocké). L’entraînement d’un modèle passe par des points de sauvegarde successifs. Le coût (en énergie) est proportionnel au nombre d’étapes d’entrainement. Il y a forcément de la déperdition en ligne car de nombreuses pièces se mettent en défaut à un moment ou à un autre (GPUs, stockage, réseau, etc.). Pour faire baisser le coût du modèle, il faut renforcer l’efficacité de l’ensemble du centre de données afin de limiter le taux de déperdition et les retours sur les points de sauvegarde précédents. On comprend ainsi la difficulté d’entraîner un modèle sur plusieurs centres de données, même si cela permettrait d’éviter des constructions géantes.
L’efficacité d’un entraînement se mesure en MFUs (Model Flops Utilization) et pour les meilleurs se situe aux alentours de 50%. Le modèle à 50% de MFU pourra être au choix plus performant ou plus économique qu’un modèle à 30% de MFU. La différence d’efficacité est déjà visible à 20 000 GPUs, elle sera flagrante à 300 000 GPUs et au delà, se chiffrant en dizaines, voire centaines de milliards de dollars. D’où l’intérêt d’une conception quasi parfaite de ces centres de données géants. Cette exigence pousse à l’intégration de toutes les pièces du centre de données plutôt qu’à une approche modulaire. C’est pourquoi il n’est pas évident que les BigTech continuent longtemps à privilégier les GPUs Nvidia par rapport à leurs solutions internes. Et c’est d’autant plus probable que les parties à faire progresser sont plutôt la connectique, le stockage et la mémoire, qui n’arrivent pas à suivre la progression des GPUs. Pourquoi laisser de telles marges à Nvidia si ses puces sont surdimensionnées par rapport aux autres éléments du centre de données ?
Enfin le dernier élément de coût à réduire est celui de l’énergie nécessaire pour faire fonctionner le centre de données. L’amélioration du MFU cité plus haut nécessite de prévoir des redondances (solutions de remplacement) qui coûtent en énergie. S’il faut une centrale électrique de bonne taille pour faire tourner un centre de données, on comprend que l’énergie est un élément important du coût global. Il faut donc:
Concevoir le centre de données de manière à ce qu’il soit le plus économe possible en électricité à MFU constant. Autrement dit, il faut maximiser le MFU par watt.
Il faut payer le moins cher possible le watt.
La différence de coût entre les protagonistes peut être colossale à terme en fonction des choix opérés. Aujourd’hui l’utilisation d’une centrale à gaz par rapport à celui d’une centrale nucléaire ne fait pas vraiment la différence (d’où les choix contrastés de xAI-turbine à gaz- et de Microsoft-nucléaire-sur l’alimentation de leurs centres). Dans une ou deux générations, il n’y aura pas le choix: nucléaire ou solaire…
Inférence
Si l’entraînement est le coût fixe à minimiser à puissance de calcul donnée, l’inférence est le coût marginal, proportionnel à l’utilisation du modèle. Les contraintes de l’inférence sont très différentes de celles de l’entraînement:
L’entraînement implique de faire travailler des dizaines ou centaines de milliers de puces ensemble sur des calculs complexes (propagation avant, rétro propagation, calcul des gradients et des poids). Ces calculs nécessitent des puces généralistes, flexible et programmée sur l’ensemble des tâches d’entraînement. D’où l’importance de CUDA ou TensorFlow par exemple.
L’inférence interroge un modèle figé. L’important est que ce modèle soit dans la mémoire de la puce ou des puces utilisées pour répondre au prompt. Les poids et gradients sont fixes. Le travail est spécialisé (propagation avant), la puce peut l’être également pour maximiser la rapidité de réponse et l’efficacité énergétique. C’est pourquoi on voit émerger des concurrents de Nvidia sur l’inférence, la flexibilité apportée par CUDA n’étant pas nécessaire. On peut citer Groq, Cerebras ou les TPUs de Google. La véritable contrainte est liée au nombre d’instances simultanées sur un modèle. Une puce peut recevoir un peu moins d’une dizaine d’instances simultanées et une instance peut être partagée sur un peu moins de dix puces au maximum. Donc en moyenne, il faut mobiliser une puce par instance. Si bien qu’un modèle qui a des millions de clients peut à la limite nécessiter des millions de puces d’inférence si tous les clients interrogent le modèle en même temps ! Les modèles de pointe occupent beaucoup de mémoire, ce qui nécessite de les faire tourner sur un cloud (les PCs et smartphones ne pouvant héberger que de petits modèles). Dès lors, les gagnants:
disposeront de centre de données géants, capables de faire de l’inférence pour des centaines de millions de requêtes simultanées.
reliés entre eux par des liaisons à haut débit permettant de transférer une tâche d’un centre à l’autre en fonction de la disponibilité et du coût énergétique à l’instant de la requête. Il faudra par exemple aller en Corée du Sud si le coût de l’énergie est moindre cher qu’aux États-Unis à certaines périodes de la journée.
possédant une infrastructure de caches localisés près des utilisateurs.
L’objectif étant de répondre précisément…et vite. L’infrastructure d’inférence doit donc être encore plus massive, connectée et géographiquement diversifiée que l’infrastructure d’entraînement afin de diminuer le coût par requête.
Combien d’acteurs seront capables de proposer entraînement et inférence sur les modèles type ChatGPT 6 ou 7 dans des conditions de coût raisonnables ? Probablement encore moins que les six précédemment nommés.
Le modèle ne sera plus une commodité
Jusqu’à ce jour, une foison de modèles LLM a pu se déployer car le coût d’entraînement est « relativement » faible et l’inférence bon marché, du fait de la petite taille et simplicité desdits modèles. Le français Mistral AI a pu se hisser dans le peloton. Le modèle est aujourd’hui une commodité, une unité de base, certes peu onéreuse, mais qui ne sait pas faire grand chose sans supervision rapprochée: beaucoup de protagonistes pour une utilité discutée. Il en sera tout autrement dans une ou deux générations de modèles. Leur qualité dépendra en premier de la puissance de calcul déployée et leur adoption du coût de cette puissance. Un modèle, aussi performant soit-il aujourd’hui, ne pourra survivre que s’il a pu s’appuyer sur d’énormes moyens financiers. Cela explique les manœuvres actuelles de sociétés comme OpenAI ou Anthropic pour lever des fonds rapidement sur des valorisations élevées ($150 milliards pour le premier, $40 milliards pour le second). Ces sociétés ne peuvent s’épanouir sans maîtriser l’infrastructure. Soit elles parviendront à lever des dizaines de milliards de dollars pour construire des centres de données, soit elles finiront dans le giron des opérateurs cloud survivants. L’intégration semble être la clé de la réussite (modèle + infrastructure+source d’énergie). Voici quelles pourraient en être les conséquences.
1/ L’Europe déclassée
Le DSA (Digital Service Act) et DMA (Digital Market Act) sont en théorie louables dans la mesure où ils veulent éviter les discours de haine et favoriser la concurrence au sein des plateformes numériques. Mais comme le dit Frédéric Bastiat, il y a ce que l’on voit et ce que l’on ne voit pas, les conséquences induites. En l’occurrence:
Ce qu’on voit: un consommateur européen protégé (DSA) et une chance pour de petits acteurs numériques de se développer en limitant le pouvoir des géants du net (DMA).
Ce qu’on ne voit pas: un système de surveillance et divulgation des algorithmes et données des grandes plateformes incompatibles avec une approche intégrée (DSA). L’obligation pour les BigTech d’adopter une approche modulaire, en permettant à des concurrents modestes de se brancher par API à leurs fonctionnalités clés.
Très simplement, l’Europe impose une approche modulaire quand le marché dicte l’inverse. Les interconnexions doivent être standard par principe. Les commissaires européens auraient gagné à lire Clayton Christensen: la modularité est un avantage quand un produit est mûr mais un inconvénient quand il a encore de grandes marges de progression, comme souvent en matière technologique. Le marché se dirige vers des centres de données géants intégrés à une source d’énergie produisant des modèles de pointe propriétaires (y compris Meta, le champion de l’open source). Comment un centre de données européen géant construit sur un terrain onéreux (permis, manque de place), nourri au charbon et gaz russe, en queue de liste d’attente pour acheter des puces Nvidia, menacé de lourdes amendes en cas d’enfreinte du RGPD, DSA, DMA ou de l’acte européen sur l’IA va-t-il pouvoir produire un modèle dernier cri efficient ?
L’Europe s’interdit ainsi d’avoir un champion du numérique. De plus, les amendes potentielles étant particulièrement salées, les grandes plateformes des Etats-Unis ont un choix limité: offrir un service dégradé aux développeurs et consommateurs européens pour ne pas mettre en péril leurs services clés; ou abandonner l’Europe (généralement moins de 10% de leur chiffre d’affaires). Non seulement les entreprises européennes ne seront plus dans la course technologique ( la création d’un ministère de l’IA ne suffira pas…), mais l’ensemble des acteurs économiques en pâtiront, ayant accès aux services d’IA déjà dépassés, sans enjeu pour leurs promoteurs. On ne mesure pas encore l’ampleur du problème car le leader OpenAI n’est pas encore dans le viseur du DSA et DMA (trop petit), mais cela va vite changer. Au delà de l’économie, on peut penser aux implications militaires d’un retard sur l’IA. Le temps joue contre l’Europe: n’ayant ni infrastructure, ni source énergétique à bas coût, elle n’aura pas de modèle non plus…et sera finalement obligée s’aplatir devant Oncle Sam, ne lui en déplaise…

2/ du copilote à l’agent
Microsoft a inventé la notion de copilote dès 2021, avant la mise sur le marché des modèles d’IA générative. Son système d’aide au codage s’appelait déjà GitHub Copilot. En 2023, il investit $10 milliards dans OpenAI et cherche un usage « professionnel » pour sa propre version de ChatGPT. Il étend alors à son modèle la notion de copilote. L’IA générative est un complément de la personne qui cherche à accomplir une tâche, elle l’augmente. Cette approche correspond parfaitement à la culture de Microsoft qui augmente déjà le travailleur avec Excel, Word ou PowerPoint. Cela arrange également Satya Nadella que Copilot ne soit pas destiné à remplacer Excel ou Word mais à l’augmenter… du fait de son taux d’hallucinations assez élevé, le LLM se prête bien à cette caractérisation de copilote: il doit être contrôlé en permanence. Il n’est donc pas directement dangereux pour l’emploi mais son utilité réelle reste à démontrer: elle est dans l’œil de l’utilisateur. Cela explique également pourquoi, au delà d’un succès de curiosité, le LLM a du mal à être intégré au coeur du fonctionnement des entreprises, il ne rapporte pas assez par rapport aux investissements effectués.
Pour justifier les investissements massifs à venir, le LLM doit changer de destination. Il ne doit pas augmenter l’individu mais le remplacer. Entre le coût d’un GPU et celui d’un salaire, le choix est vite fait. En devenant un agent (capable d’exécuter une suite de tâches à la place de quelqu’un), le LLM justifiera un prix relativement élevé tout en restant attractif. Le marché pourra alors se développer massivement. C’est exactement comme le marché de la voiture autonome: tant que la voiture aura besoin d’un superviseur, l’adoption sera limitée. En revanche, supprimez le superviseur et le potentiel devient énorme.
Marc Benioff, CEO de Salesforce a compris qu’il fallait abandonner le copilote au profit de l’agent. Lors de sa dernière Keynote, il a critiqué l’approche de Microsoft pour mettre en avant son changement de cap: créer des agents permettant aux entreprises de faire des économies tangibles. La nouveauté la plus intéressante est la tarification qui ne se fera plus au nombre d’utilisateurs (censés diminuer), mais au volume traité:
Lorsque nous envisagerons la tarification, elle sera basée sur la consommation", a déclaré M. Benioff. "Et lorsque nous pensons à cela, nous pensons à dire à nos clients - et nous l'avons fait - qu'il s'agit d'environ 2 dollars par conversation.
Le fait que cette nouvelle conception vienne de Salesforce est intéressante à plusieurs titres:
-Salesforce est une société de bonne taille
-qui a inventé le cloud, précurseur des sociétés SAAS (Software As A Service)
-et notamment la tarification du logiciel par abonnement, rompant avec la logique de la licence (SAP)
Elle est probablement la société la mieux placée pour impulser un nouveau modèle économique et de tarification pour les sociétés SAAS.
3/ Modèles et données
Limites des LLMs
Le problème est que dans l’état actuel des modèles et de leurs hallucinations, les agents vont être difficiles à mettre en œuvre. Marc Benioff se vante d’avoir mille agents dans les cartons mais de quoi seront-ils capables ? Les LLM d’aujourd’hui produisent des token, les uns après les autres en fonction de la séquence déjà produite. Le principe est de produire le token le plus probable selon la séquence précédente mais avec parfois un changement et un token peu probable. C’est ce principe qui permet la créativité du modèle. Produire le token le plus probable systématiquement donne à l’expérience de mauvais résultats. Cependant, quand une erreur se produit dans la séquence, il y a de fortes chances pour que les token suivants ne répondent plus au prompt initial et que la réponse finale soit hallucinatoire. C’est comme si le modèle déraillait à partir de la production d’un « mauvais »5 token, de manière irréparable. Cela n’est pas forcément gênant quand on écrit un poème. En revanche c’est rédhibitoire quand on veut produire une instruction. Plus l’instruction sera complexe, plus il y aura de token et donc de chances que le modèle déraille, donnant une mauvaise instruction. Cela explique pourquoi les LLMs restent aujourd’hui des bots avec leur lot d’hallucinations, sans capacité d’actions, donc sans capacité de remplacer des salariés.
L’importance des données
Pour éviter les hallucinations, dans l’état actuel de la puissance de calcul et des modèles, il faut compter sur la préparation des données, dans le but d’éliminer les « mauvais » token et canaliser les réponses. Cette préparation est inadaptée aux modèles grands publics qui doivent répondre aux requêtes les plus variées, elle est en revanche ajustée aux entreprises qui ont une direction stratégique et des moyens à mettre en œuvre pour l’atteindre. Elle appelle cependant à un travail en profondeur sur les données certes mais aussi sur les flux de travail des entreprises pour les repenser, en lien avec l’IA. C’est ce que propose par exemple Palantir avec son « système d’exploitation » Foundry, réceptacle des données enregistrées par des entreprises clientes. Il s’agit aujourd’hui autant d’un travail de consultant que d’achat d’un logiciel. Cela explique le succès de Palantir par rapport à des sociétés qui ne proposent que le logiciel (sociétés SAAS6) ou que le Consulting.
Un LLM qui raisonne
OpenAI permet aux abonnés ChatGPT plus d’expérimenter son dernier modèle en date, ChatGPT o-1. Ce modèle constitue un réel progrès par rapport au LLM de base, car il est capable de corriger le tir en cas de « mauvais » token. Il est entraîné à raisonner, c’est à dire à décomposer un prompt en séquences adaptées et à vérifier la réponse. A l’inférence, il va alors décomposer le prompt en chaînes de raisonnements (suivant ce qu’il a appris), puis se corriger en cas de réponse inadéquate. Avant de donner sa réponse définitive, il va donc produire beaucoup plus de token qu’un LLM classique jusqu’à correction des hallucinations. Plus l’inférence est longue, moins la réponse à de chances d’être erronée. Un tel modèle est idéal pour donner des instructions mais très cher à l’inférence. La conséquence inéluctable est de pousser les acteurs de l’IA à changer le mode d’utilisation de ces modèles vers les tâches d’agents potentiellement mieux rémunérés que les bots. Salesforce sera probablement un promoteur de ChatGPT o-1….et des modèles concurrents. La seule limite est l’infrastructure.
Les LLM, dont la première version est ChatGPT o-1, sont capables de produire des token de raisonnement. Il s’agit là d’un saut de génération qui rend encore plus inéluctable la construction d’infrastructures géantes intégrées. Il y a désormais une course entre le modèle et l’infrastructure (qui devance qui ?), à l’instar de la course entre Intel et Windows dans les années 90. L’enjeu est simplement beaucoup plus grand.
Bonne semaine,
Hervé
La **NVIDIA H100** est une unité de traitement graphique (GPU) Tensor Core, introduite en 2022 et basée sur l'architecture Hopper de NVIDIA. Elle est conçue pour des applications d'intelligence artificielle (IA), d'inférence en IA, et de calcul haute performance (HPC) dans les centres de données.
API=Application programing interface ou interface de programmation d’application en français.
PPE=Property, plant and equipment.
dans de rares cas, plusieurs centres de données se coordonnent pour entraîner un modèle (ex Google)
Sur le web, il y a à peu près tout…et n’importe quoi. Le modèle peut ainsi être entraîné sur des éléments inexacts.
Software As A Service